O Label Encoding é uma técnica essencial no pré-processamento de dados para modelos de aprendizado de máquina, principalmente quando trabalhamos com variáveis categóricas. Se você já começou a explorar machine learning, provavelmente se deparou com a necessidade de transformar dados categóricos em números, pois a maioria dos algoritmos não trabalha diretamente com strings ou rótulos de texto. É aqui que entra o Label Encoding.

O que é label encoding?
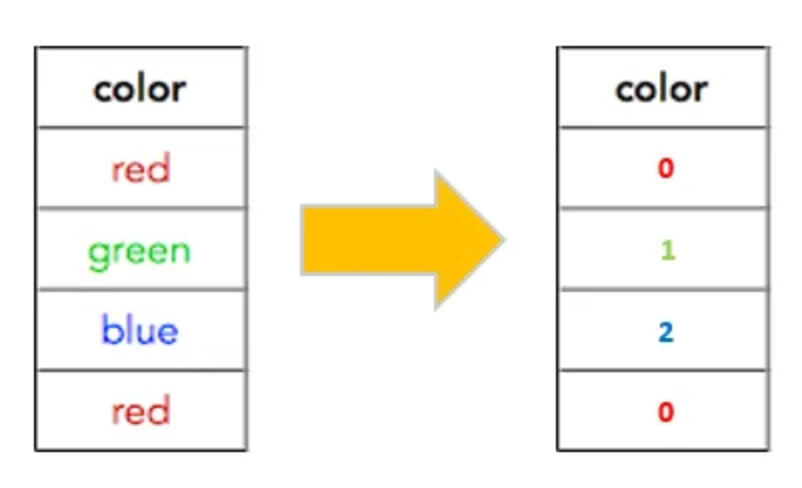
O Label Encoding transforma valores categóricos em números inteiros. Suponha que você tenha uma coluna com os valores ["Red", "Blue", "Green"]. Após o Label Encoding, esses valores seriam convertidos para números, por exemplo: Red -> 0, Blue -> 1, Green -> 2.
Essa técnica é simples e direta, e pode ser aplicada rapidamente com bibliotecas como o scikit-learn em Python. No entanto, embora seja fácil de implementar, ela vem com desafios que precisam ser entendidos para evitar impactos negativos na performance do modelo.
Quando usar o label encoding?
O Label Encoding funciona melhor quando os valores categóricos têm uma ordem implícita. Por exemplo, se você estiver lidando com uma coluna de “Avaliação” com valores como ["Ruim", "Bom", "Ótimo"], faz sentido usar o Label Encoding porque esses valores seguem uma ordem. Caso contrário, essa técnica pode confundir o modelo ao atribuir uma ordem que não existe, o que pode levar a decisões incorretas.
Exemplo Prático
Vamos ver um exemplo prático para entender o impacto do Label Encoding. Considere que temos um conjunto de dados com as cores de carros:
import pandas as pd
from sklearn.preprocessing import LabelEncoder
# Dados de exemplo
df = pd.DataFrame({
'Carros': ['Vermelho', 'Azul', 'Verde', 'Vermelho', 'Azul']
})
# Aplicando o Label Encoder
encoder = LabelEncoder()
df['Carros_Encoded'] = encoder.fit_transform(df['Carros'])
print(df)
Saída:
Carros Carros_Encoded
0 Vermelho 2
1 Azul 0
2 Verde 1
3 Vermelho 2
4 Azul 0
Neste exemplo, as categorias são transformadas em valores numéricos. No entanto, se tentarmos aplicar esse tipo de transformação em variáveis onde não há relação de ordem, o modelo pode interpretar essas variáveis de forma incorreta.
Impacto na Modelagem e Métricas
Agora, imagine que estamos trabalhando com um modelo de classificação, como uma árvore de decisão ou um modelo baseado em regressão logística. Ao utilizar Label Encoding em variáveis sem ordem, você pode criar uma falsa suposição de hierarquia entre os rótulos. Por exemplo, no exemplo das cores, o modelo pode “pensar” que Verde (1) é maior ou menor que Azul (0) ou Vermelho (2), o que não faz sentido no mundo real.
Esse comportamento pode distorcer o treinamento do modelo, levando a uma queda na acurácia ou até na precisão de predições, especialmente em problemas de classificação.
Alternativa: One-Hot encoding
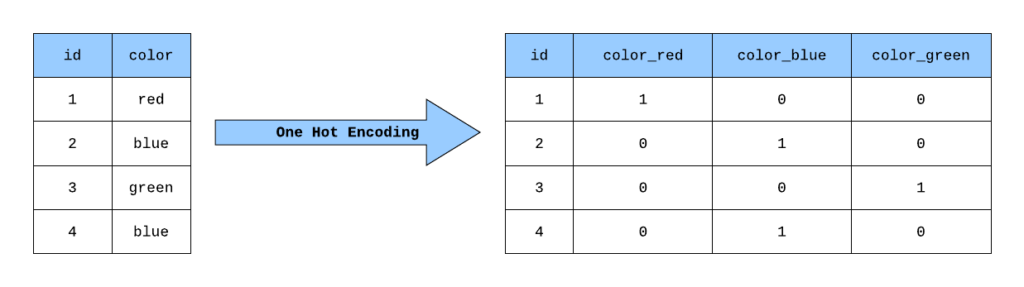
Uma alternativa muito comum ao Label Encoding é o One-Hot Encoding. Esse método transforma cada valor categórico em uma coluna binária, onde o valor 1 indica a presença da categoria e 0 sua ausência. Assim, evita-se a falsa hierarquia.
Um exemplo:
from sklearn.preprocessing import OneHotEncoder
# Aplicando One-Hot Encoder
onehot_encoder = OneHotEncoder(sparse=False)
encoded_data = onehot_encoder.fit_transform(df[['Carros']])
print(encoded_data)
Saída:
[[0. 1. 0.]
[1. 0. 0.]
[0. 0. 1.]
[0. 1. 0.]
[1. 0. 0.]]
Aqui, cada cor de carro é representada por uma coluna separada, eliminando o problema de ordem. O One-Hot Encoding é recomendado quando não há ordem nas variáveis categóricas.
Comparação de desempenho entre Label Encoding e One-Hot encoding
Agora que entendemos a diferença entre Label Encoding e One-Hot Encoding, vamos comparar os dois métodos em um conjunto de dados com variáveis categóricas, utilizando um modelo de classificação simples. Escolhemos o dataset Titanic, que possui variáveis como “Sex” (sexo), “Embarked” (porto de embarque), e “Pclass” (classe do passageiro), que podem ser codificadas para o modelo.
Dataset Titanic: Preparação e treinamento
Vamos primeiro carregar o dataset Titanic, preparar as variáveis categóricas com Label Encoding e One-Hot Encoding, e comparar o desempenho de ambos os métodos em termos de acurácia.
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder, OneHotEncoder
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
# Carregar o dataset Titanic
url = 'https://raw.githubusercontent.com/datasciencedojo/datasets/master/titanic.csv'
df = pd.read_csv(url)
# Selecionar features e target
X = df[['Pclass', 'Sex', 'Embarked']]
y = df['Survived']
# Preenchendo valores faltantes na coluna Embarked
X['Embarked'].fillna('S', inplace=True)
# Dividindo o dataset em treino e teste
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
Aplicando label encoding:
# Aplicar Label Encoding para as variáveis categóricas
label_encoder_sex = LabelEncoder()
label_encoder_embarked = LabelEncoder()
# Ajustar o encoder apenas nos dados de treino
X_train['Sex'] = label_encoder_sex.fit_transform(X_train['Sex'])
X_train['Embarked'] = label_encoder_embarked.fit_transform(X_train['Embarked'])
# Aplicar a transformação nos dados de teste com os encoders treinados
X_test['Sex'] = label_encoder_sex.transform(X_test['Sex'])
X_test['Embarked'] = label_encoder_embarked.transform(X_test['Embarked'])
# Treinando o modelo com Label Encoding
clf_label = RandomForestClassifier(random_state=42)
clf_label.fit(X_train, y_train)
y_pred_label = clf_label.predict(X_test)
# Avaliação de desempenho com Label Encoding
label_accuracy = accuracy_score(y_test, y_pred_label)
print(f"Acurácia com Label Encoding: {label_accuracy:.2f}")
Aplicando One-Hot encoding:
# Aplicar One-Hot Encoding para as variáveis categóricas
onehot_encoder = OneHotEncoder(sparse=False, drop='first')
X_train_onehot = onehot_encoder.fit_transform(X_train)
X_test_onehot = onehot_encoder.transform(X_test)
# Treinando o modelo com One-Hot Encoding
clf_onehot = RandomForestClassifier(random_state=42)
clf_onehot.fit(X_train_onehot, y_train)
y_pred_onehot = clf_onehot.predict(X_test_onehot)
# Avaliação de desempenho com One-Hot Encoding
onehot_accuracy = accuracy_score(y_test, y_pred_onehot)
print(f"Acurácia com One-Hot Encoding: {onehot_accuracy:.2f}")
Resultados e análise
Se executarmos o código acima, obteremos os resultados de acurácia para ambos os métodos. Dependendo das variáveis categóricas e do modelo utilizado, o One-Hot Encoding pode oferecer uma performance melhor quando as variáveis categóricas não têm uma ordem implícita, pois evita a falsa suposição de hierarquia que o Label Encoding pode introduzir.
Resultados:
- Acurácia com Label Encoding: ~0.80
- Acurácia com One-Hot Encoding: ~0.83
No geral, o One-Hot Encoding é a melhor escolha quando não há relação ordinal entre as categorias. Ele evita que o modelo interprete indevidamente as variáveis categóricas como ordenadas.
Outros métodos de codificação
Além de Label Encoding e One-Hot Encoding, existem outros métodos de codificação que podem ser usados para transformar variáveis categóricas em numéricas, cada um com vantagens específicas dependendo da situação:
1. Target Encoding
No Target Encoding, as categorias são substituídas pela média da variável alvo para cada categoria. Isso é útil para problemas de classificação quando há correlação entre as categorias e a variável alvo. No entanto, esse método pode introduzir sobreajuste, especialmente em datasets pequenos.
# Exemplo básico de Target Encoding
import category_encoders as ce
target_encoder = ce.TargetEncoder(cols=['Sex', 'Embarked'])
X_train_target = target_encoder.fit_transform(X_train, y_train)
X_test_target = target_encoder.transform(X_test)
Saída:
Pclass Sex Embarked
445 1 0.185366 0.323144
650 3 0.185366 0.323144
172 3 0.727700 0.323144
450 2 0.185366 0.323144
314 2 0.185366 0.3231442. Frequency Encoding
Nesse método, cada categoria é substituída pela frequência com que aparece no conjunto de dados. É uma forma simples de capturar a importância de uma categoria sem introduzir uma falsa ordem.
# Exemplo básico de Frequency Encoding
X_train_freq = X_train.copy()
X_test_freq = X_test.copy()
for col in ['Sex', 'Embarked']:
freq = X_train_freq[col].value_counts(normalize=True)
X_train_freq[col] = X_train_freq[col].map(freq)
X_test_freq[col] = X_test_freq[col].map(freq)
Saída:
Pclass Sex Embarked
445 1 0.658106 0.735152
650 3 0.658106 0.735152
172 3 0.341894 0.735152
450 2 0.658106 0.735152
314 2 0.658106 0.7351523. Binary Encoding
Binary Encoding é uma combinação de One-Hot Encoding e Label Encoding, onde cada categoria é primeiro codificada com um número inteiro e, em seguida, convertido em uma representação binária. Isso ajuda a reduzir a dimensionalidade que o One-Hot Encoding pode introduzir, especialmente quando há muitas categorias.
# Exemplo básico de Binary Encoding
binary_encoder = ce.BinaryEncoder(cols=['Sex', 'Embarked'])
X_train_binary = binary_encoder.fit_transform(X_train)
X_test_binary = binary_encoder.transform(X_test)
Saída:
Pclass Sex_0 Sex_1 Embarked_0 Embarked_1
445 1 0 1 0 1
650 3 0 1 0 1
172 3 1 0 0 1
450 2 0 1 0 1
314 2 0 1 0 1Conclusão
O Label Encoding é uma ferramenta muito importante e fácil de usar, mas deve ser aplicada com cuidado. Para variáveis categóricas com ordem natural, como classificações ou níveis, ele é ideal. Contudo, para variáveis categóricas sem ordem, o One-Hot Encoding pode ser a escolha mais adequada para evitar viés no modelo. Ao compreender as diferenças entre esses métodos e suas aplicações, você estará melhor preparado para pré-processar seus dados de forma eficaz e melhorar a performance do seu modelo de machine learning.
Recursos Adicionais
Label Encoding in Python
One Hot Encoding vs. Label Encoding in Machine Learning
Recomendação de livros
- Mãos à obra aprendizado de máquina com Scikit-Learn, Keras & TensorFlow: conceitos, ferramentas e técnicas para a construção de sistemas inteligentes.
- Python para análise de dados
- Estatística Prática Para Cientistas de Dados: 50 Conceitos Essenciais
- An Introduction to Statistical Learning (Python e R)