
Neste tutorial, implementaremos um agente simples capaz de receber perguntas através de uma interface no streamlit e fornecer respostas interagindo diretamente com dados armazenados em arquivos CSV ou pandas DataFrame. Ao combinar a capacidade de processamento de linguagem natural dos Grandes Modelos de Linguagem (LLMs) com a flexibilidade da biblioteca Python Pandas, construiremos um chatbot capaz de responder a consultas sobre seus dados de forma precisa e explicar de que forma ele chegou até esse resultado.
Por que isso é útil?
Ao integrar inteligência artificial com análise de dados, você pode:
- Automatizar consultas complexas: Perguntar em linguagem natural e obter respostas a partir de um DataFrame.
- Explorar dados de maneira intuitiva: Evitar o código manual repetitivo para manipulação de dados.
- Criar interfaces interativas: Permitir que qualquer pessoa faça perguntas sobre o dataset através de uma aplicação web.
Tecnologias usadas para criar o agente
- LangChain: Framework que facilita o uso de LLMs (Large Language Models) para gerar respostas com base em dados ou prompts.
- OpenAI: API que fornece modelos avançados de linguagem, como o GPT-3.5, que utilizaremos para gerar respostas inteligentes.
- Pandas: Biblioteca para manipulação de dados em Python, muito usada para trabalhar com arquivos CSV.
- Streamlit: Ferramenta que facilita a criação de interfaces web em Python para visualização de dados e interação com usuários.
Passo a passo para a criação do agente
Passo 1: Configuração Inicial
Primeiro, carregue as variáveis de ambiente (como a chave da API OpenAI) e o arquivo CSV que pode ser baixado no kaggle e importe as bibliotecas necessárias para a criação do agent.
import os
import pandas as pd
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI
from langchain_experimental.agents.agent_toolkits import create_pandas_dataframe_agent
# Carregar variáveis de ambiente do arquivo .env
load_dotenv()
Crie um arquivo chamado “.env” para guardar a chave da API OpenAI, exemplo:
OPENAI_API_KEY=sk-proj-xxxxxxxxx-xxxxx-xxxx-xxxxxxxxxPasso 2: Configuração da chave e do modelo LLM
Nesta etapa vamos configurar o nosso modelo que será o gpt-3.5-turbo da OpenAI e carregar o nosso arquivo .csv com os dados que usaremos para interagir como o agente.
# Configuração da chave da API OpenAI e do modelo LLM
openai_key = os.getenv('OPENAI_API_KEY')
llm_name = 'gpt-3.5-turbo'
model = ChatOpenAI(api_key=openai_key, model=llm_name)
# Carregar arquivo CSV e tratar valores ausentes
df = pd.read_csv('data/salaries.csv').fillna(value=0)
Aqui, garantimos que o arquivo CSV (salaries.csv) está carregado em um DataFrame Pandas e qualquer valor nulo é preenchido com 0.
Passo 3: Criando o agente com LangChain
Com o DataFrame em mãos, criamos um agente LangChain que será responsável por receber perguntas e interagir com os dados.
# Criar agente pandas para manipulação do DataFrame
agent = create_pandas_dataframe_agent(llm=model, df=df, verbose=True)
Este agente usará o modelo da OpenAI para analisar as informações do DataFrame e gerar respostas com base nas consultas.
Passo 4: Definindo o Prompt
O agente precisa de um “prompt” específico para lidar com as perguntas de forma eficaz. Criamos um “prefixo” e “sufixo” para orientar o modelo a trabalhar com o DataFrame e sempre revisar suas respostas antes de enviá-las.
O prefixo é o conjunto de instruções ou contexto que vem antes da pergunta principal ou tarefa. Ele define como o modelo deve preparar o ambiente, organizando os dados ou realizando uma configuração inicial para que possa responder adequadamente à pergunta. O objetivo do prefixo é garantir que o modelo entenda o contexto dos dados e esteja pronto para processá-los corretamente.
O sufixo é o conjunto de instruções que vem após a pergunta principal. Ele serve para definir o que o agente deve fazer depois de processar a pergunta e chegar a uma resposta. O sufixo garante que o modelo siga uma abordagem detalhada e estruturada, oferecendo uma reflexão crítica sobre a resposta e apresentando-a da maneira mais clara e rigorosa possível.
PROMPT_PREFIX = """
First, adjust the pandas display settings to show all columns.
Retrieve the column names, then proceed to answer the question based on the data.
"""
PROMPT_SUFFIX = """
- **Before providing the final answer**, always try at least one additional method.
Reflect on both methods and ensure that the results address the original question accurately.
- Format any figures with four or more digits using commas for readability.
- If the results from the methods differ, reflect, and attempt another approach until both methods align.
- If you're still unable to reach a consistent result, acknowledge uncertainty in your response.
- Once confident in the correct answer, craft a detailed and well-structured explanation using markdown.
- **Under no circumstances should prior knowledge be used**—rely solely on the results derived from the data and calculations performed.
- As part of your final answer, include an **Explanation** section that clearly outlines how the answer was reached, mentioning specific column names used in the calculations.
"""
Esse prompt orienta o agente a tentar diferentes métodos, refletir sobre os resultados, e só então fornecer uma resposta final detalhada, sempre baseada no que foi calculado.
Passo 5: Criando a interface do agente com Streamlit
Usamos o Streamlit para criar uma interface onde o usuário pode fazer perguntas e ver as respostas geradas pelo agente.
import streamlit as st
st.title("Database AI Agent with Langchain")
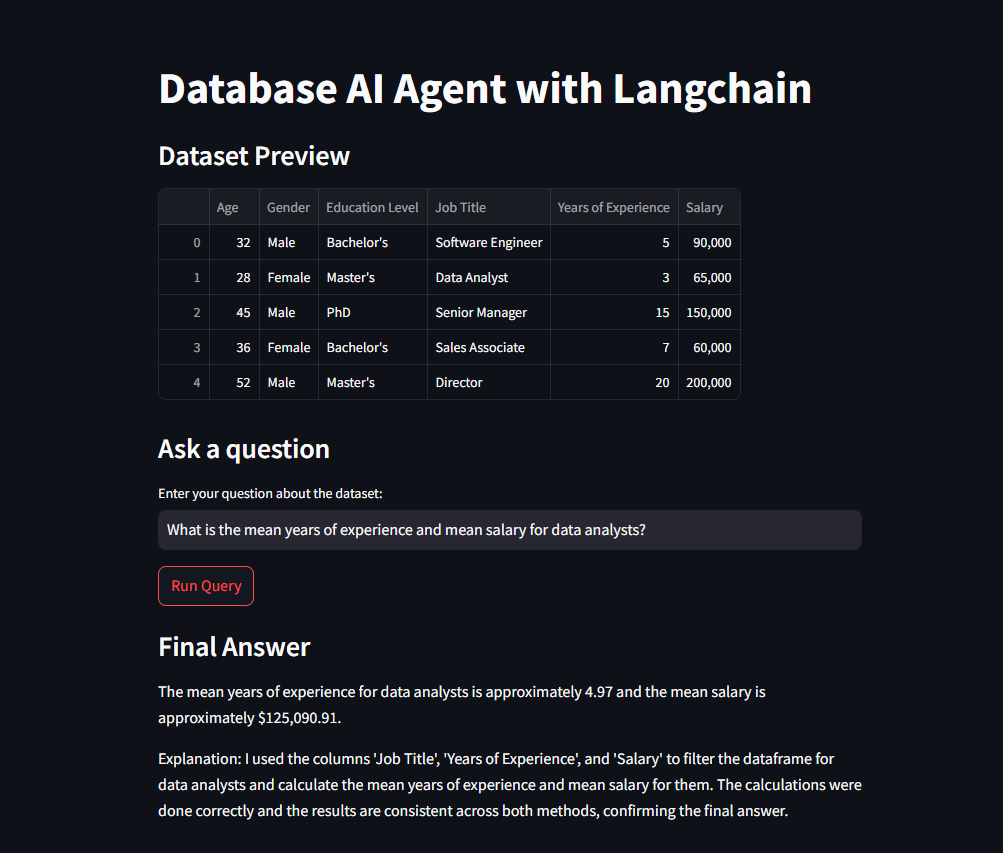
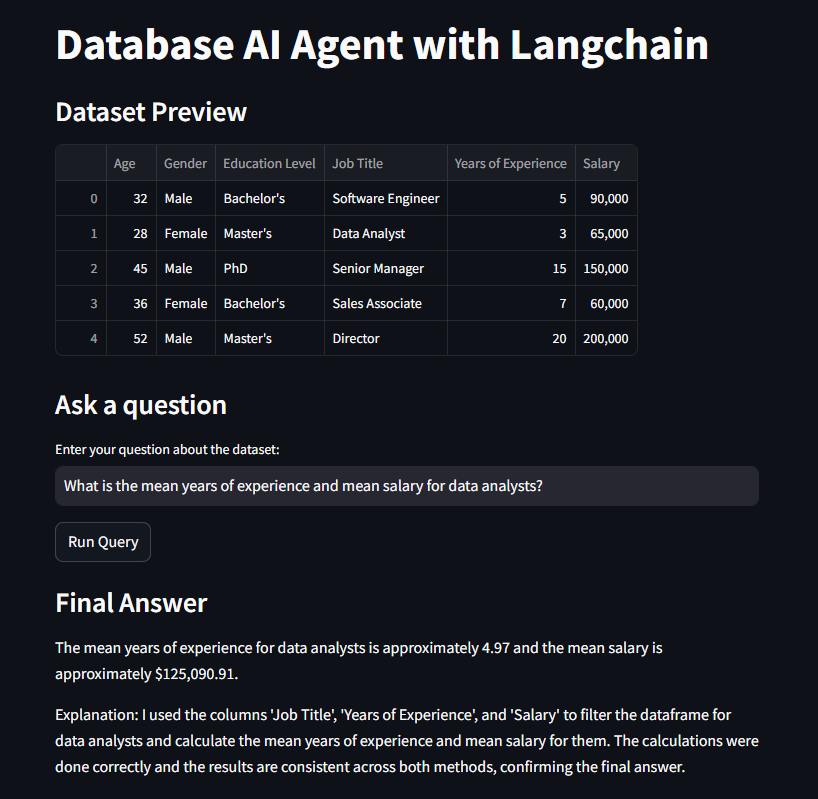
st.write("### Dataset Preview")
st.write(df.head())
# Entrada de pergunta pelo usuário
st.write('### Ask a question')
question = st.text_input(
"Enter your question about the dataset:",
"What is the mean years of experience for the job with the highest mean salary?"
)
# Ação ao clicar no botão
if st.button("Run Query"):
QUERY = PROMPT_PREFIX + question + PROMPT_SUFFIX
res = agent.invoke(QUERY)
st.write("### Final Answer")
st.markdown(res["output"])
Com essa interface, o usuário pode visualizar uma prévia do DataFrame e fazer perguntas sobre os dados diretamente. Quando o botão “Run Query” é pressionado, a pergunta é enviada para o agente, que retorna a resposta final.
Passo 6: Executar o streamlit
No seu terminal, execute o comando para criar a interface web através do streamlit
streamlit run nome_do_arquivo.pyCódigo completo
import os
import pandas as pd
import streamlit as st
from dotenv import load_dotenv
from langchain.schema import HumanMessage, SystemMessage
from langchain_openai import ChatOpenAI
from langchain_experimental.agents.agent_toolkits import create_pandas_dataframe_agent
# Carregar variáveis de ambiente do arquivo .env
load_dotenv()
# Configuração da chave da API OpenAI e do modelo LLM
openai_key = os.getenv('OPENAI_API_KEY')
llm_name = 'gpt-3.5-turbo'
model = ChatOpenAI(api_key=openai_key, model=llm_name)
# Carregar arquivo CSV e tratar valores ausentes
df = pd.read_csv('data/salaries.csv').fillna(value=0)
# Criar agente pandas para manipulação do DataFrame
agent = create_pandas_dataframe_agent(llm=model, df=df, verbose=True)
# Definir prefixo e sufixo do prompt para o agente
PROMPT_PREFIX = """
First, adjust the pandas display settings to show all columns.
Retrieve the column names, then proceed to answer the question based on the data.
"""
PROMPT_SUFFIX = """
- **Before providing the final answer**, always try at least one additional method.
Reflect on both methods and ensure that the results address the original question accurately.
- Format any figures with four or more digits using commas for readability.
- If the results from the methods differ, reflect, and attempt another approach until both methods align.
- If you're still unable to reach a consistent result, acknowledge uncertainty in your response.
- Once confident in the correct answer, craft a detailed and well-structured explanation using markdown.
- **Under no circumstances should prior knowledge be used**—rely solely on the results derived from the data and calculations performed.
- As part of your final answer, include an **Explanation** section that clearly outlines how the answer was reached, mentioning specific column names used in the calculations.
"""
# Exemplo de pergunta ao agente
QUESTION = "What is the mean years of experience for the job with the highest mean salary?"
QUERY = PROMPT_PREFIX + QUESTION + PROMPT_SUFFIX
# Consulta e execução da resposta do agente
res = agent.invoke(QUERY)
# Aplicação Streamlit
st.title("Database AI Agent with Langchain")
st.write("### Dataset Preview")
st.write(df.head())
# Entrada de pergunta pelo usuário
st.write('### Ask a question')
question = st.text_input(
"Enter your question about the dataset:",
"What is the mean years of experience for the job with the highest mean salary?"
)
# Ação ao clicar no botão
if st.button("Run Query"):
QUERY = PROMPT_PREFIX + question + PROMPT_SUFFIX
res = agent.invoke(QUERY)
st.write("### Final Answer")
st.markdown(res["output"])
Ao final você terá um agente com interface web capaz de receber perguntas e devolver respostas através de um processo de análise de dados com o pandas. Explicando como quais colunas e métodos utilizados para chegar a resposta final.
Próximos passos
Importe os dados para um banco de dados SQL: Pois são genéricos para qualquer tipo de dados estruturados, por isso é útil ler as técnicas SQL mesmo se você estiver usando o Pandas para análise de dados CSV, também garantindo um maior nível de segurança no acesso a base de dados.
Uso de ferramentas (tools): Técnica geral que gera saída estruturada de um modelo e você pode usá-la mesmo quando não pretende invocar nenhuma ferramenta. Um exemplo de caso de uso disso é a extração de texto não estruturado.
Memória: A memória é fundamental para que os modelos de linguagem mantenham um contexto consistente ao longo de uma conversa. Ao armazenar o histórico de interações, a memória permite que o modelo gere respostas mais relevantes e personalizadas, adaptando-se às informações previamente fornecidas pelo usuário.
Conclusão
Neste tutorial, aprendemos a construir uma aplicação interativa que combina LangChain, OpenAI e Streamlit para fazer consultas inteligentes em um dataset. Esse tipo de solução pode ser aplicado a diferentes tipos de datasets e ajustado para perguntas complexas em várias áreas, como finanças, saúde, e-commerce, entre outras.
Gostou do post? Deixe seu comentário ou pergunta abaixo e siga nosso blog para mais tutoriais práticos sobre inteligência artificial e desenvolvimento!
Recomendação de livros



