
Nos últimos anos, os Large Language Models (LLMs) como GPT-3 e GPT-4 revolucionaram o processamento de linguagem natural (NLP) com sua capacidade de gerar texto coerente e informativo. No entanto, esses modelos têm limitações, especialmente quando se trata de fornecer informações atualizadas ou responder a consultas muito específicas. É aqui que entra o RAG, ou Retrieval-Augmented Generation.
O que é RAG?
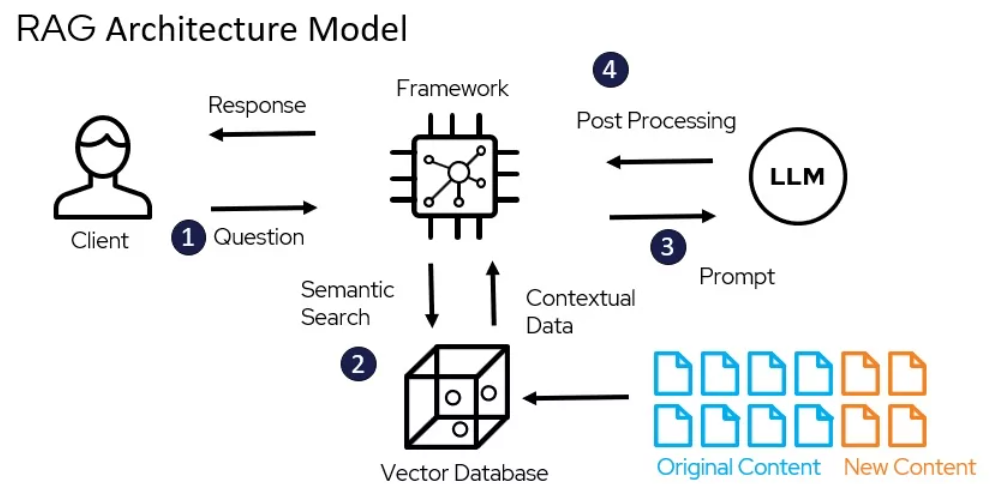
O RAG é uma técnica que combina a recuperação de informações (retrieval) com a geração de texto (generation) para melhorar a precisão e relevância das respostas geradas por LLMs. Enquanto os LLMs tradicionais dependem exclusivamente de seu treinamento prévio, o RAG permite que o modelo recupere informações de uma base de dados ou documento relevante antes de gerar uma resposta. Isso torna as respostas mais precisas e contextuais.
Por que usar RAG?
Embora os LLMs sejam incrivelmente poderosos, eles são limitados pelo conhecimento presente no momento do treinamento. Isso significa que, sem acesso a informações atualizadas, eles podem fornecer respostas desatualizadas ou imprecisas. O RAG resolve essa limitação ao permitir que o modelo acesse dados em tempo real ou informações específicas de um domínio, aprimorando significativamente a qualidade das respostas.
Imagine que dentro da sua empresa você acessa um LLM como o ChatGPT ou Gemini e pergunta através do chat: “Qual foi o resultado de arrecadação da empresa no mês de Agosto de 2024?”
Ele provalmente não saberá responder ou dará uma resposta bastante imprecisa, isso porque ou ele não tem acesso a essa informação ou ela está publica, mas é uma informação muito recente, é aqui que o RAG entra em cena.
Como o RAG Funciona
A arquitetura do RAG pode ser dividida em dois componentes principais: o módulo de recuperação (retrieval) e o módulo de geração (generation).
- Módulo de Recuperação: Este componente é responsável por buscar documentos relevantes de uma base de dados usando uma consulta fornecida. Essa busca pode ser feita utilizando técnicas tradicionais de recuperação de informações, como BM25, ou modelos de recuperação neural mais sofisticados, como BERT.
- Módulo de Geração: Após a recuperação dos documentos, o módulo de geração usa essas informações como contexto para gerar uma resposta mais precisa. O LLM utiliza os documentos recuperados para fundamentar e contextualizar a resposta, combinando o conhecimento armazenado internamente com o conteúdo recém-recuperado.
Passo a passo do processo
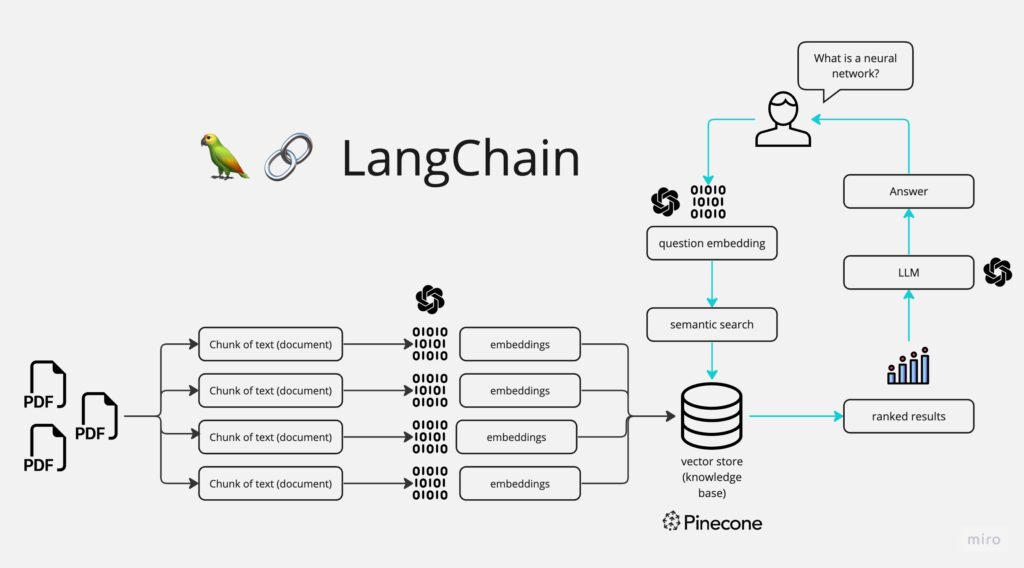
1. Entrada do Usuário: O usuário faz uma pergunta, como “O que é uma rede neural?”. Essa pergunta é transformada em um vetor numérico, conhecido como embedding.
2. Embedding da Pergunta: O sistema usa a query para buscar informações relevantes em fontes de conhecimento, que podem ser bancos de dados, documentos, ou APIs de informações em tempo real.
3. Busca Semântica: O embedding da pergunta é comparado com os embeddings de um conjunto de documentos (por exemplo, PDFs) que foram previamente transformados em vetores. Essa comparação é feita em um banco de dados vetorial, como o Pinecone. A busca semântica permite encontrar os documentos mais relevantes para a pergunta, mesmo que não haja uma correspondência exata de palavras.
4. Recuperação de Documentos: Os documentos mais relevantes são recuperados do banco de dados vetorial. A relevância é determinada pela similaridade entre o embedding da pergunta e os embeddings dos documentos.
5. Processamento dos Documentos: Os documentos recuperados são processados por um modelo de linguagem grande (LLM), como o GPT-4. O LLM utiliza esses documentos como contexto para gerar uma resposta à pergunta do usuário.
6. Geração da Resposta: O LLM gera uma resposta completa e informativa, baseada tanto na compreensão da pergunta quanto no conhecimento extraído dos documentos relevantes.
Vector Search e embedding models
Para que uma aplicação RAG seja eficaz, é necessário que ela encontre e forneça ao LLM as informações mais relevantes à consulta do usuário. A tarefa de selecionar os textos mais relevantes dentre milhões de documentos representa um desafio considerável. Para superá-lo, utilizamos a técnica de Busca Vetorial. Essa técnica consiste em representar tanto as consultas dos usuários quanto os documentos de uma base de conhecimento como vetores numéricos em um espaço vetorial. A similaridade entre esses vetores indica a relevância do documento em relação à consulta, permitindo a recuperação eficiente da informação mais pertinente.
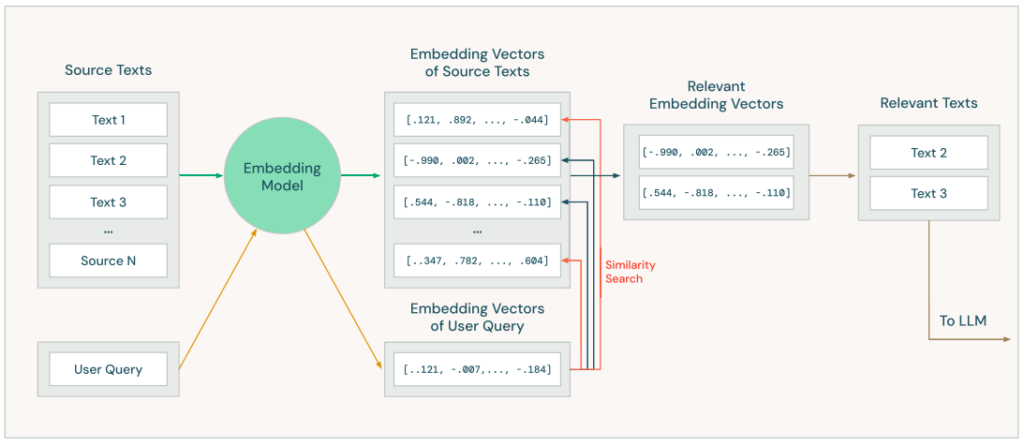
Esses vetores representam o significado dos textos, o que possibilita uma busca baseada em significado. No entanto, é importante lembrar que o significado capturado pelos modelos de embeddings pode não ser exatamente o desejado, por isso é necessário testar e avaliar cada componente da aplicação RAG.
Vantagens e desafios do RAG
Vantagens:
- Acesso a Informações Atualizadas: O RAG permite que LLMs acessem dados atualizados em tempo real, tornando as respostas mais precisas.
- Personalização das Respostas: As respostas podem ser personalizadas com base em dados específicos do usuário ou de um domínio, aumentando a relevância.
- Melhoria na Precisão: Ao combinar recuperação e geração, o RAG melhora a precisão das respostas, especialmente em consultas complexas ou específicas.
Desafios e limitações:
- Dependência de Dados de Qualidade: A eficácia do RAG depende da qualidade dos dados recuperados. Se a base de dados estiver desatualizada ou for irrelevante, a resposta gerada pode ser igualmente imprecisa.
- Complexidade de Implementação: Implementar um sistema RAG em produção pode ser mais complexo do que usar LLMs tradicionais, exigindo uma infraestrutura robusta para gerenciamento de dados e recuperação de informações.
Aplicações Práticas de RAG
O RAG tem uma ampla gama de aplicações práticas, como:
- Assistentes Virtuais: Melhorar a precisão das respostas em assistentes virtuais, especialmente em áreas que requerem informações atualizadas, como saúde e finanças.
- Motores de Busca Personalizados: Criar motores de busca que oferecem resultados mais personalizados e relevantes, combinando a recuperação tradicional com geração de texto.
- Sistemas de Suporte ao Cliente: Fornecer respostas mais precisas e contextuais em sistemas de suporte ao cliente, usando dados específicos da empresa ou do cliente.
Conclusão
O RAG representa um avanço significativo na geração de texto por LLMs, combinando o melhor da recuperação de informações com a geração de texto para fornecer respostas mais precisas e relevantes. Seja em assistentes virtuais, motores de busca ou sistemas de suporte ao cliente, o RAG já está transformando a maneira como interagimos com a IA e está ao nosso alcance para a criação de ferramentas baseadas em LLM que podem ser muito úteis para o dia a dia.
Recursos Adicionais
Guia sobre RAG do databrics
O que é RAG segundo a Amazon
Recomendação de livros: Recomendações



