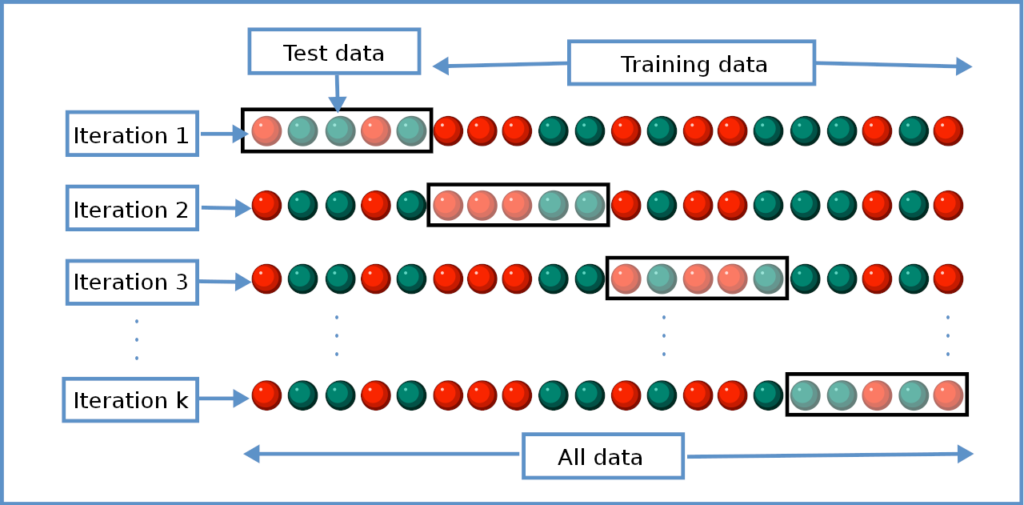
A validação cruzada é uma técnica fundamental em machine learning empregada para avaliar de forma rigorosa a capacidade de generalização de um modelo. Ao dividir os dados em diferentes subconjuntos e iterativamente treinar e testar o modelo em diferentes combinações desses subconjuntos, é possível obter uma estimativa mais precisa e confiável do desempenho do modelo em dados nunca antes vistos.
Problema da Generalização
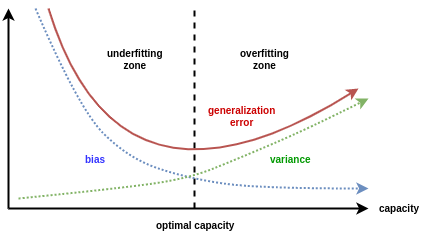
Um dos objetivos principais em machine learning é desenvolver modelos capazes de fazer previsões precisas sobre dados novos e nunca antes vistos. No entanto, encontrar o equilíbrio ideal entre um modelo que se ajusta excessivamente aos dados de treinamento (overfitting) e um modelo que não captura os padrões subjacentes dos dados (underfitting) é um desafio constante. A validação cruzada surge como uma técnica eficaz para mitigar esses problemas, permitindo uma avaliação mais robusta e confiável do desempenho de um modelo.
Métodos de Validação Cruzada
Existem vários métodos de validação cruzada, cada um com suas próprias vantagens e desvantagens:
1. K-fold Cross-Validation
A validação cruzada K-Fold é um dos métodos mais populares e amplamente utilizados para validar modelos de machine learning. Ele é especialmente útil para avaliar o desempenho de um modelo de maneira robusta, garantindo que ele generalize bem para dados não vistos.

Como funciona o K-Fold Cross-Validation?
O processo de K-Fold Cross-Validation pode ser resumido nos seguintes passos:
- Divisão dos Dados: O conjunto de dados é dividido em K subconjuntos mutuamente exclusivos, chamados de folds. O valor de K é escolhido pelo usuário, sendo 5 ou 10 valores comuns.
- Iteração e Treinamento: O modelo é treinado K vezes. Em cada iteração, um fold diferente é usado como conjunto de validação, enquanto os K-1 folds restantes são usados como conjunto de treinamento.
- Avaliação do Modelo: A performance do modelo é avaliada em cada uma das K iterações, gerando K métricas de performance (como acurácia, precisão, recall, F1-score, etc.).
- Média das Métricas: Ao final das K iterações, as métricas de desempenho são médias para obter uma estimativa final do desempenho do modelo
Vantagens da K-fold Cross-Validation:
- Estimação mais precisa do erro de generalização: Ao realizar múltiplas iterações, a validação cruzada fornece uma estimativa mais confiável do desempenho do modelo em dados não vistos.
- Evita viés: A divisão aleatória dos dados em folds ajuda a reduzir o viés na estimativa do erro.
- Flexibilidade: Permite comparar diferentes modelos e ajustar hiperparâmetros de forma mais eficiente.
Implementação em Python:
import numpy as np
from sklearn.model_selection import KFold
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_iris
from sklearn.metrics import accuracy_score
# Carregar o conjunto de dados
data = load_iris()
X, y = data.data, data.target
# Definir o modelo
model = RandomForestClassifier()
# Definir o K-Fold Cross-Validation
kf = KFold(n_splits=5, shuffle=True, random_state=42)
accuracies = []
# Iterar sobre cada fold
for train_index, test_index in kf.split(X):
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
# Treinar o modelo
model.fit(X_train, y_train)
# Prever no conjunto de teste
y_pred = model.predict(X_test)
# Avaliar a acurácia
accuracy = accuracy_score(y_test, y_pred)
accuracies.append(accuracy)
# Média das acurácias
mean_accuracy = np.mean(accuracies)
print(f'Acurácia Média: {mean_accuracy}')
Acurácia Média: 0.96000000000000022. Stratified K-Fold Cross-Validation
A validação cruzada estratificada K-Fold é uma variação da validação cruzada K-Fold que preserva a distribuição das classes em cada fold. Isso significa que cada fold terá aproximadamente a mesma proporção de classes que o conjunto de dados original. Esse método é especialmente útil para conjuntos de dados desbalanceados, onde certas classes são significativamente menos representadas do que outras.
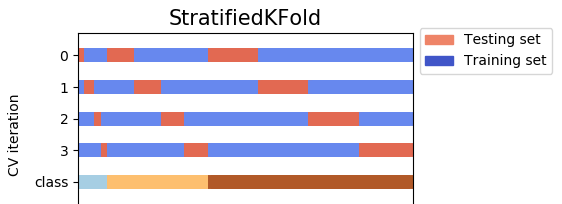
Como Funciona o Stratified K-Fold Cross-Validation?
O processo de Stratified K-Fold Cross-Validation pode ser descrito da seguinte forma:
- Divisão dos Dados: O conjunto de dados é dividido aleatoriamente em K partes ou “folds”. No entanto, ao invés de uma divisão simples, a estratificação garante que a proporção das classes seja preservada em cada fold.
- Iteração e Treinamento: O modelo é treinado K vezes. Em cada iteração, um fold diferente é usado como conjunto de validação, enquanto os K-1 folds restantes são usados como conjunto de treinamento.
- Avaliação do Modelo: A performance do modelo é avaliada em cada uma das K iterações, gerando K métricas de performance.
- Média das Métricas: As métricas de performance obtidas são então promediadas para fornecer uma estimativa final do desempenho do modelo.
Vantagens do Stratified K-Fold Cross-Validation:
- Preservação da Distribuição das Classes: Garantir que cada fold tenha a mesma distribuição de classes que o conjunto de dados original ajuda a obter uma avaliação mais representativa do desempenho do modelo, especialmente em dados desbalanceados.
- Redução de Variabilidade: Assim como no K-Fold tradicional, ao promediar os resultados de K iterações, a variabilidade na estimativa do desempenho do modelo é reduzida.
- Melhor Generalização: Ajuda a evitar que o modelo aprenda de forma enviesada devido à distribuição desigual das classes.
Implementação em Python:
import numpy as np
from sklearn.model_selection import StratifiedKFold
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_iris
from sklearn.metrics import accuracy_score
# Carregar o conjunto de dados
data = load_iris()
X, y = data.data, data.target
# Definir o modelo
model = RandomForestClassifier()
# Definir o Stratified K-Fold Cross-Validation
skf = StratifiedKFold(n_splits=5, shuffle=True, random_state=42)
accuracies = []
# Iterar sobre cada fold
for train_index, test_index in skf.split(X, y):
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
# Treinar o modelo
model.fit(X_train, y_train)
# Prever no conjunto de teste
y_pred = model.predict(X_test)
# Avaliar a acurácia
accuracy = accuracy_score(y_test, y_pred)
accuracies.append(accuracy)
# Média das acurácias
mean_accuracy = np.mean(accuracies)
print(f'Acurácia Média: {mean_accuracy}')
Acurácia Média: 0.9533333333333335O conjunto de dados iris é dividido em 5 folds estratificados. O modelo RandomForestClassifier é treinado e testado em cada fold, e as acurácias de cada iteração são armazenadas e promediadas para obter uma acurácia média. Esta acurácia média fornece uma estimativa mais confiável do desempenho do modelo do que uma única divisão de treinamento/teste, especialmente em dados desbalanceados.
3. Leave-One-Out Cross-Validation (LOOCV)
Leave-One-Out Cross-Validation (LOOCV) ou deixe um de fora é uma técnica de validação cruzada onde o conjunto de dados é dividido de forma que cada observação é usada uma vez como conjunto de validação, enquanto todas as outras observações são usadas como conjunto de treinamento. É um caso especial de K-Fold Cross-Validation onde o número de folds K é igual ao número de observações no conjunto de dados.
Caso de uso
Um caso de uso comum para Leave-One-Out Cross-Validation é em análise de dados biológicos e médicos, especialmente quando se lida com conjuntos de dados pequenos e valiosos. Por exemplo, imagine que você esteja desenvolvendo um modelo para prever a probabilidade de um paciente desenvolver uma doença específica com base em seu perfil genético. Os conjuntos de dados genéticos frequentemente têm um número limitado de amostras devido ao custo e complexidade da coleta de dados, então é crucial utilizar cada observação disponível para maximizar a quantidade de informações extraídas e obter uma estimativa confiável do desempenho do modelo.
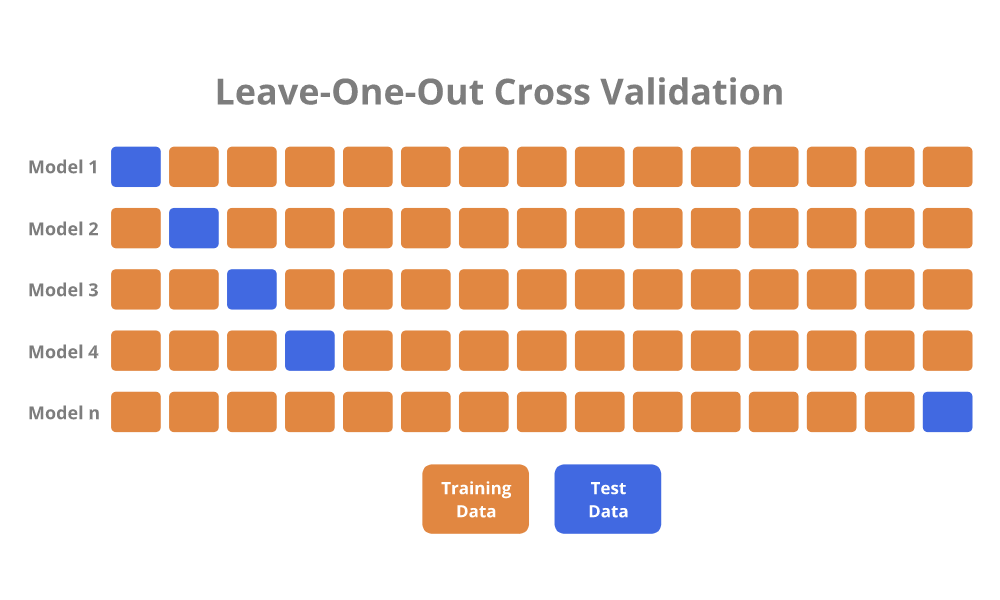
Como Funciona o Leave-One-Out Cross-Validation?
O processo de LOOCV pode ser descrito da seguinte forma:
- Iteração sobre cada Observação: Para cada observação no conjunto de dados, essa única observação é usada como o conjunto de validação, e o restante das observações são usadas como conjunto de treinamento.
- Treinamento e Validação: O modelo é treinado usando o conjunto de treinamento e avaliado usando o conjunto de validação.
- Cálculo das Métricas de Desempenho: A métrica de desempenho (como acurácia, erro quadrático médio, etc.) é calculada para cada iteração.
- Média das Métricas: As métricas de desempenho obtidas em cada iteração são então promediadas para fornecer uma estimativa final do desempenho do modelo.
Vantagens do Leave-One-Out Cross-Validation:
- Uso Completo dos Dados: Todos os dados são utilizados tanto para treinamento quanto para validação.
- Redução do Viés: Como cada observação é usada como conjunto de validação, o viés na estimativa do desempenho do modelo é minimizado.
- Detecção de Variabilidade: Fornece uma medida clara de como pequenas mudanças nos dados podem afetar o desempenho do modelo.
Desvantagens do Leave-One-Out Cross-Validation:
- Custo Computacional Elevado: Para grandes conjuntos de dados, LOOCV pode ser computacionalmente caro, pois o modelo precisa ser treinado NNN vezes, onde NNN é o número de observações.
- Alta Variabilidade: Pode ter alta variabilidade, especialmente em conjuntos de dados pequenos, pois cada iteração depende fortemente de uma única observação.
Implementação em Python:
import numpy as np
from sklearn.model_selection import LeaveOneOut
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_iris
from sklearn.metrics import accuracy_score
# Carregar o conjunto de dados
data = load_iris()
X, y = data.data, data.target
# Definir o modelo
model = RandomForestClassifier()
# Definir o Leave-One-Out Cross-Validation
loo = LeaveOneOut()
accuracies = []
# Iterar sobre cada observação
for train_index, test_index in loo.split(X):
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
# Treinar o modelo
model.fit(X_train, y_train)
# Prever no conjunto de teste
y_pred = model.predict(X_test)
# Avaliar a acurácia
accuracy = accuracy_score(y_test, y_pred)
accuracies.append(accuracy)
# Média das acurácias
mean_accuracy = np.mean(accuracies)
print(f'Acurácia Média: {mean_accuracy}')
Acurácia Média: 0.94666666666666674. Validação por método Holdout
O Holdout Method é uma técnica simples e direta de validação de modelos de machine learning. Ele envolve dividir o conjunto de dados original em dois subconjuntos separados: um conjunto de treinamento e um conjunto de teste. O modelo é treinado no conjunto de treinamento e avaliado no conjunto de teste.
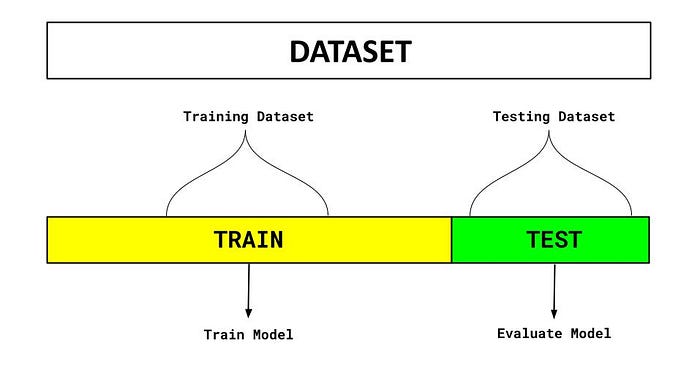
Como Funciona o método Holdout?
O processo do Holdout pode ser descrito da seguinte forma:
- Divisão dos Dados: O conjunto de dados original é dividido aleatoriamente em dois subconjuntos: um conjunto de treinamento e um conjunto de teste. Uma divisão comum é usar 70-80% dos dados para treinamento e 20-30% para teste.
- Treinamento do Modelo: O modelo de machine learning é treinado usando apenas o conjunto de treinamento.
- Avaliação do Modelo: Após o treinamento, o modelo é avaliado no conjunto de teste usando métricas de performance adequadas (como acurácia, precisão, recall, F1-score, etc.).
Vantagens do método Holdout:
- Simplicidade e Facilidade de Implementação: O Holdout Method é simples de entender e fácil de implementar.
- Baixo Custo Computacional: Como o modelo é treinado apenas uma vez, o custo computacional é menor em comparação com métodos como K-Fold ou LOOCV.
- Eficiência em Conjuntos de Dados Grandes: Para conjuntos de dados grandes, uma única divisão pode ser suficiente para fornecer uma estimativa confiável do desempenho do modelo.
Desvantagens do método Holdout:
- Dependência da Divisão: A performance do modelo pode variar significativamente dependendo de como os dados são divididos. Uma única divisão pode não ser representativa do desempenho real do modelo.
- Uso Ineficiente dos Dados: Apenas uma parte dos dados é usada para treinamento, o que pode ser uma desvantagem quando se tem um conjunto de dados pequeno.
Implementação em Python:
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_iris
from sklearn.metrics import accuracy_score
# Carregar o conjunto de dados
data = load_iris()
X, y = data.data, data.target
# Dividir o conjunto de dados em treinamento (70%) e teste (30%)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# Definir o modelo
model = RandomForestClassifier()
# Treinar o modelo no conjunto de treinamento
model.fit(X_train, y_train)
# Prever no conjunto de teste
y_pred = model.predict(X_test)
# Avaliar a acurácia
accuracy = accuracy_score(y_test, y_pred)
print(f'Acurácia: {accuracy}')
Acurácia: 1.0Conclusão
A validação de modelos é uma etapa crucial no processo de desenvolvimento de modelos de machine learning, pois permite avaliar a performance e a capacidade de generalização dos modelos para novos dados. Diversos métodos de validação são empregados, cada um com suas vantagens e desvantagens, e a escolha do método adequado depende das características do conjunto de dados e dos requisitos do projeto.
Implementar e comparar diferentes métodos de validação em seus projetos de machine learning pode levar a uma melhor compreensão do comportamento dos modelos e, em última análise, a modelos mais eficientes e eficazes para resolver problemas complexos.
Leituras Adicionais:
Validação cruzada k-fold
5 Motivos para usar validação cruzada
Validação cruzada em machine learning
Livros Recomendados
- Mãos à obra aprendizado de máquina com Scikit-Learn, Keras & TensorFlow: conceitos, ferramentas e técnicas para a construção de sistemas inteligentes.
- Python para análise de dados
- Estatística Prática Para Cientistas de Dados: 50 Conceitos Essenciais
- An Introduction to Statistical Learning (Python e R)