
Você não pode entender algo a menos que você possa construir isso, foi que disse Seymour Papert e isso é um fato para quem deseja aprender machine learning além da superfície, pensando nisso iniciamos essa série de implementação de machine learning from scratch.
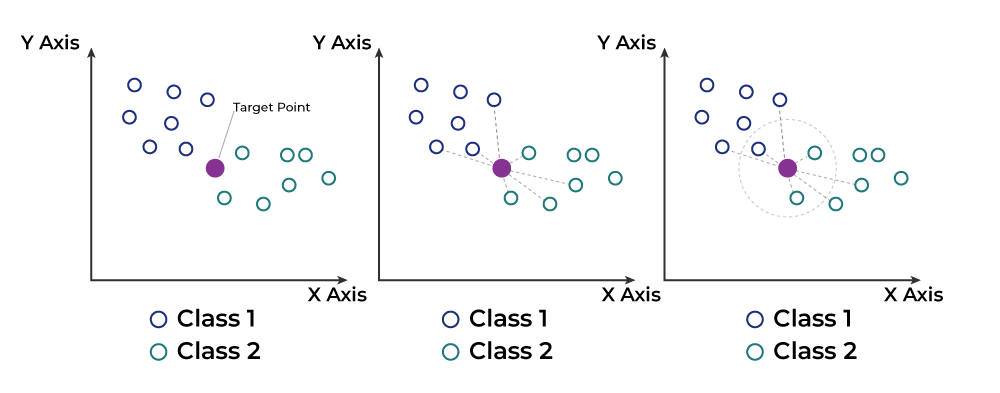
O algoritmo K-vizinhos mais próximos (KNN) é um dos algoritmos de aprendizado supervisionado mais simples e intuitivos, utilizado tanto para problemas de classificação quanto de regressão. No KNN, a previsão para uma amostra de teste é feita com base nos K exemplos de treinamento mais próximos dessa amostra. A proximidade é geralmente determinada usando uma medida de distância, como a distância euclidiana.
Tipo de aprendizado: Baseado em instância
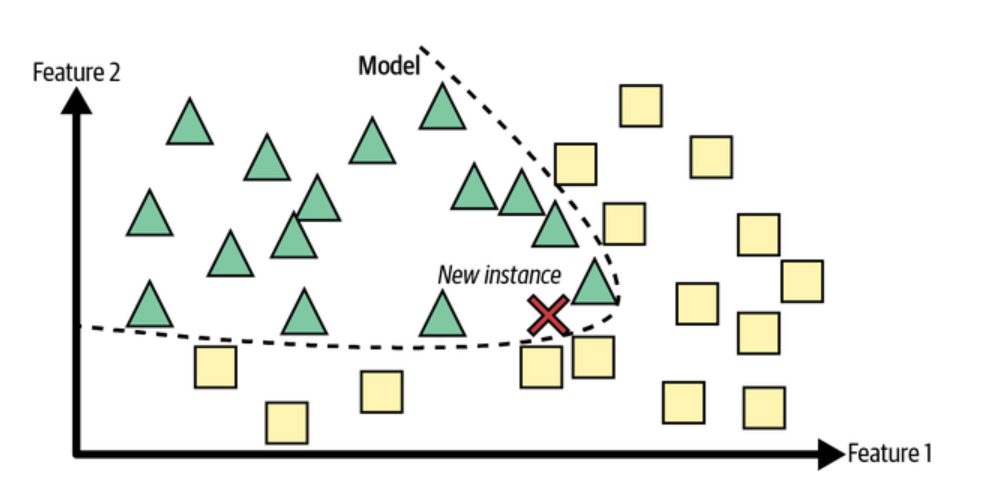
A classificação K-Nearest Neighbors (KNN) é uma técnica que utiliza o aprendizado baseado em instância. Em vez de criar um modelo geral a partir dos dados de treinamento, o KNN armazena todos os exemplos de treinamento. Quando o modelo precisa fazer uma previsão para um novo exemplo (ou instância de teste), ele compara esse novo exemplo com os exemplos armazenados e encontra os mais parecidos (os vizinhos mais próximos).
Características do KNN (K vizinhos mais próximos):
- Armazenamento dos Dados: Todos os exemplos de treinamento são armazenados.
- Comparação: Quando um novo exemplo aparece, o KNN compara esse exemplo com todos os exemplos armazenados, medindo a “distância” entre eles.
- Previsão: A partir dos exemplos mais próximos, o KNN determina a classe do novo exemplo. Para isso, ele vê qual é a classe mais comum entre os vizinhos mais próximos (no caso de classificação) ou calcula a média dos valores (no caso de regressão).
Aprendizado Preguiçoso
O KNN é chamado de método de aprendizado preguiçoso porque ele não faz nenhuma generalização ou aprendizado até que uma nova instância precise ser classificada. Em vez de criar um modelo antecipadamente, ele espera até que precise fazer uma previsão e então encontra a resposta com base nos exemplos armazenados.
Estimativa Local
Em vez de estimar uma função que serve para todo o conjunto de dados, o KNN estima a função alvo localmente, ou seja, de forma específica para cada nova instância que precisa ser classificada. Isso significa que cada previsão pode ser diferente, pois depende dos exemplos de treinamento mais próximos da nova instância.
Funcionamento do Algorítimo
- Escolha de K: O valor de K é um hiperparâmetro que deve ser escolhido cuidadosamente. Valores pequenos de K podem ser sensíveis ao ruído nos dados, enquanto valores grandes podem suavizar a previsão excessivamente.
- Cálculo da Distância: Calcula-se a distância entre a amostra de teste e todas as amostras de treinamento.
- Seleção dos Vizinhos: Seleciona-se os K exemplos de treinamento mais próximos (menor distância) da amostra de teste.
- Votação ou Média:
- Para classificação, a previsão é a classe mais comum entre os K vizinhos (votação majoritária).
- Para regressão, a previsão é a média dos valores dos K vizinhos.
KNN from scratch com Python
1. Importação das Bibliotecas
import numpy as np
from collections import Counter
from sklearn import datasets
Importa a biblioteca numpy para manipulação de arrays, Counter do módulo collections para contar a frequência das classes e datasets para carregarmos o nosso dataset disponível no sklearn.
2. Dados de Treinamento
# Carrega os dados do dataset iris
iris = datasets.load_iris()
# Define as variáveis preditoras (X) e target (y)
X, y = iris.data, iris.target
# Separa os dados entre treino e teste
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=1234)
# Plot dos dados
plt.figure()
plt.scatter(X[:,2], X[:,3], c=y, cmap=cmap, edgecolors='k', s=20)
plt.show()
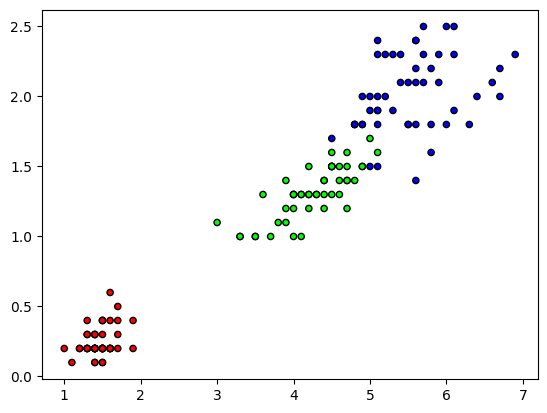
Ao carregarmos o dataset iris, podemos observar 3 classes: Iris-setosa, Iris-versicolor e Iris-virginica, nosso objetivo é usar o KNN para classifica-las de acordo com as suas caracteristicas fornecidas na variável preditora X.
3. Número de Vizinhos
k = 3
O “k” representa o número de vizinhos mais próximos considerados no problema
4. Armazenamento das Previsões
predictions = []
Inicializa uma lista vazia para armazenar as previsões
5. Loop para cada ponto dos dados de teste
for x in X_test:
# Calcula a distância euclidiana entre x e todos os pontos de treinamento
distances = []
for x_train in X_train:
distance = np.sqrt(np.sum((x - x_train) ** 2))
distances.append(distance)
Ao imprimirmos as 3 primeiras saídas desse looping, podemos observar:
X_test: [6.1 3. 4.6 1.4]
X_train: [5.1 2.5 3. 1.1]
Distância Euclidiana: 1.974
X_test: [6.1 3. 4.6 1.4]
X_train: [6.2 2.8 4.8 1.8]
Distância Euclidian: 0.500
X_test: [6.1 3. 4.6 1.4]
X_train: [5. 3.5 1.3 0.3]
Distância Euclidiana: 3.682Para cada ponto de teste (X_test), calcula a distância euclidiana entre o ponto de teste e todos os pontos de treinamento (X_train) e armazena as distâncias em uma lista (distances).
6. Conversão das Distâncias para Numpy Array
distances = np.array(distances)
Converte a lista de distâncias para um array numpy
7. Encontra os k Pontos Mais Próximos
k_indices = np.argsort(distances)[:k]
k_indices: [ 51 111 113]Encontra os índices dos k pontos de treinamento mais próximos, lembrando que definimos que k=3
8. Etiquetas dos Vizinhos Mais Próximos
k_nearest_labels = [y_train[i] for i in k_indices]
k_nearest_labels: [0, 0, 0]Encontra as etiquetas (classes) dos k vizinhos mais próximos.
9. Determina a Classe Mais Comum
most_common = Counter(k_nearest_labels).most_common(1)
most_common: [(0, 3)]Determina a classe mais comum entre os vizinhos mais próximos.
10. Adiciona a previsão para a lista de previsões
predictions.append(most_common[0][0])
11. Converte a lista de previsões para um array numpy
predictions = np.array(predictions)
12. Imprime as previsões feitas pelo algoritmo KNN que implementamos
print("Predições from scratch:", predictions)
Predições from scratch:
[ 1 1 2 0 1 0 0 0 1 2 1 0 2 1 0 1 2 0 2 1 1 1 1 1 2 0 2 1 2 0 1 1 2 0 1 0 0
0 1 2 1 0 2 1 0 1 2 0 2 1 1 1 1 1 2 0 2 1 2 0 1 1 2 0 1 0 0 0 1 2 1 0 2 1
0 1 2 0 2 1 1 1 1 1 2 0 2 1 2 0 1 1 2 0 1 0 0 0 1 2 1 0 2 1 0 1 2 0 2 1 1
1 1 1 2 0 2 1 2 0]Código from scratch completo
# Importação das bibliotecas
import numpy as np
from collections import Counter
from sklearn import datasets
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
from matplotlib.colors import ListedColormap
cmap = ListedColormap(['#FF0000', '#00FF00', '#0000FF'])
# Carrega os dados do dataset iris
iris = datasets.load_iris()
# Define as variáveis preditoras (X) e target (y)
X, y = iris.data, iris.target
# Separa os dados entre treino e teste
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=1234)
# Plot dos dados
plt.figure()
plt.scatter(X[:,2], X[:,3], c=y, cmap=cmap, edgecolors='k', s=20)
plt.show()
# Número de vizinhos a considerar
k = 3
# Armazena as previsões para os dados de teste
predictions = []
# Para cada ponto de teste
for x in X_test:
# Calcula a distância euclidiana entre x e todos os pontos de treinamento
distances = []
for x_train in X_train:
distance = np.sqrt(np.sum((x - x_train) ** 2))
distances.append(distance)
# Converte a lista de distâncias para um array numpy
distances = np.array(distances)
# Encontra os índices dos k pontos mais próximos
k_indices = np.argsort(distances)[:k]
# Encontra as etiquetas dos k vizinhos mais próximos
k_nearest_labels = [y_train[i] for i in k_indices]
# Determina a classe mais comum entre os vizinhos
most_common = Counter(k_nearest_labels).most_common(1)
# Adiciona a previsão para a lista de previsões
predictions.append(most_common[0][0])
# Converte a lista de previsões para um array numpy
predictions = np.array(predictions)
# Imprime as previsões
print("Predições from scratch:", predictions)
Implementação com o Scikitlearn
Agora que você já sabe implementar o KNN, você pode usar a bibliteca scikitlearn para faciltar o seu uso.
from sklearn.neighbors import KNeighborsClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# Carregando um dataset de exemplo (Iris)
data = load_iris()
X, y = data.data, data.target
# Dividindo o dataset em treino e teste
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Criando e treinando o modelo KNN
model = KNeighborsClassifier(n_neighbors=3)
model.fit(X_train, y_train)
# Fazendo previsões
y_pred = model.predict(X_test)
# Avaliando o modelo
accuracy = accuracy_score(y_test, y_pred)
print("Acurácia com scikit-learn:", accuracy)
Acurácia com scikit-learn: 1.0Conclusão
Em resumo, entender e implementar o KNN do zero é uma excelente maneira de consolidar seus conhecimentos em machine learning. Isso não apenas aprimora sua capacidade de aplicar o KNN de forma eficaz, mas também fornece uma base sólida para aprender e implementar outros algoritmos e técnicas na área de ciência de dados.
Leituras Adicionais:
Guide to K-Nearest Neighbors Algorithm in Machine Learning
Implementation of K-Nearest Neighbors from Scratch using Python
KNN (K-Nearest Neighbors)
Livros Recomendados: Recomendações




Pingback: Machine Learning from scratch: Implementando o SVM (Máquinas de Vetores de Suporte) em Python - IA Com Café
Pingback: Machine Learning from Scratch: Implementando K-Means Clustering em Python - IA Com Café