
Neste tutorial, vamos desenvolver nosso primeiro projeto de machine learning completo, abordando todas as etapas essenciais e mais comuns: desde a coleta de dados, passando pela Análise Exploratória de Dados (EDA), pré-processamento, seleção de features, treinamento do modelo, avaliação de desempenho, até o deploy final. Este guia fornecerá uma base sólida para entender e aplicar cada uma dessas etapas em projetos futuros.

Objetivo do projeto
O objetivo deste projeto de machine learning é prever se um solicitante terá seu empréstimo aprovado ou não, com base em um conjunto de características pessoais e financeiras. A predição de aprovação de empréstimo é baseada em diversas variáveis que influenciam a decisão final. O modelo de machine learning será treinado para aprender padrões e relações entre essas variáveis e o resultado da aprovação, que é o alvo (ou label) que queremos prever. Com um modelo bem treinado, será possível fornecer uma previsão rápida e precisa sobre a probabilidade de um empréstimo ser aprovado para novos solicitantes, auxiliando na tomada de decisões de crédito.
Dados Utilizados para o Treinamento
O modelo será treinado com um conjunto de dados que inclui as seguintes variáveis:
- Loan_ID: Identificação única de cada solicitação de empréstimo.
- Gender: Gênero do solicitante.
- Married: Status de casamento do solicitante.
- Dependents: Número de dependentes do solicitante.
- Education: Nível de escolaridade do solicitante.
- Self_Employed: Indicação se o solicitante é autônomo.
- ApplicantIncome: Renda mensal do solicitante.
- CoapplicantIncome: Renda mensal do co-solicitante, se houver.
- LoanAmount: Valor solicitado de empréstimo.
- Loan_Amount_Term: Prazo do empréstimo em meses.
- Credit_History: Histórico de crédito do solicitante.
- Property_Area: Localização do imóvel do solicitante.
- Loan_Status: Status de aprovação do empréstimo, que será o alvo (label) do modelo.
A base de dados, bem como todos os códigos que serão utilizados neste tutorial podem ser encontrados neste repositório.
Preparando o ambiente de desenvolvimento
- Escolha a sua IDE de preferência, neste tutorial utilizaremos o VSCode
- Crie uma nova pasta para o seu projeto, aqui chamamos de “LOAN_PREDICTION”
- Abra o terminal de sua preferência na IDE e vamos criar o ambiente virtual
- Para criar o ambiente virtual, vamos utilizar a biblioteca venv.
# Criar um ambiente virtual
python -m venv .venv
# Ativar o ambiente virtual
cd .venv/Scripts
activate
O ambiente virtual é utilizado para isolar a versão do Python e das bibliotecas usadas em um determinado sistema.
Instalando as bibliotecas necessárias
Agora precisamos instalar todas as bibliotecas necessárias do Python dentro do nosso ambiente virtual, (garanta que o ambiente está ativado).
pip install pandas numpy matplotlib seaborn scikit_learn streamlit imblearn
Criando o nosso Notebook para analisar os dados
1. Crie um notebook jupyter, aqui vamos chamar de grant_loan_prediction.ipynb
2. Importar as bibliotecas necessárias:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# Import para o treinamento
import sklearn
# Ignorar os Warnings
import warnings
warnings.filterwarnings("ignore")
3. Definir um estilo para as nossas visualizações
plt.style.use('fivethirtyeight')
4. Faça download do nosso dataset chamado “LoanData.csv” que se encontra no repositório e coloque ele na pasta local no projeto.
5. Faça o carregamento do dataset para um DataFrame do pandas, vamos chama-lo de “data”
data = pd.read_csv('LoanData.csv')
6. Vamos ler as primeiras 5 amostras deste DataFrame
data.head()

7. Verificando o tamanho da base de dados
data.shape
(614, 13)
# 614 linhas e 13 columnas8. Análises estatísticas dos valores numéricos
data.describe()
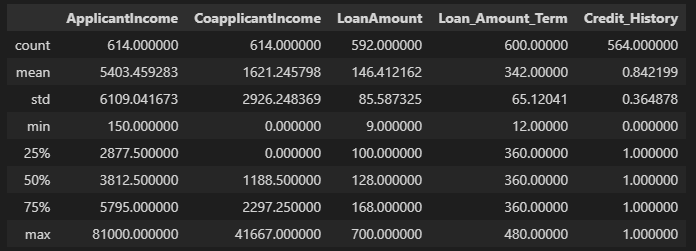
Aqui podemos analisar informações como: Média, Desvio Padrão, Máximo, Mínimo, Percentils e outros
9. Também podemos descrever as variáveis categóricas
data.describe(include = 'object')

Tratamento de valores nulos e outliers
1. Verificando se existem valores nulos
data.isnull().sum()
Loan_ID 0
Gender 13
Married 3
Dependents 15
Education 0
Self_Employed 32
ApplicantIncome 0
CoapplicantIncome 0
LoanAmount 22
Loan_Amount_Term 14
Credit_History 50
Property_Area 0
Loan_Status 0
dtype: int64Podemos observar que existem várias colunas que contém valores nulos, precisamos tratar esses valores com preenchimento ou remoção para que possamos treinar o modelo corretamente.
Para as variáveis categoricas vamos usar o valor da moda (maior frequencia) para preencher os valores nulos
data['Gender'] = data['Gender'].fillna(data['Gender'].mode()[0])
data['Married'] = data['Married'].fillna(data['Married'].mode()[0])
data['Dependents'] = data['Dependents'].fillna(data['Dependents'].mode()[0])
data['Self_Employed'] = data['Self_Employed'].fillna(data['Self_Employed'].mode()[0])
Para as variáveis numéricas vamos usar o valor da mediana (valor do meio) para preencher os valores nulos
data['LoanAmount'] = data['LoanAmount'].fillna(data['LoanAmount'].median())
data['Loan_Amount_Term'] = data['Loan_Amount_Term'].fillna(data['Loan_Amount_Term'].median())
data['Credit_History'] = data['Credit_History'].fillna(data['Credit_History'].median())
Vamos verificar novamente se ainda existem valores nulos
data.isnull().sum().sum()
np.int64(0)Agora vamos analisar a existência de outliers no nosso dataset, para isso vamos usar o gráfico boxplot
plt.style.use('fivethirtyeight')
plt.rcParams['figure.figsize'] = (15, 4)
plt.subplot(1, 3, 1)
sns.boxplot(data['ApplicantIncome'])
plt.subplot(1, 3, 2)
sns.boxplot(data['CoapplicantIncome'])
plt.subplot(1, 3, 3)
sns.boxplot(data['LoanAmount'])
plt.suptitle('Outilers in the data')
plt.show()
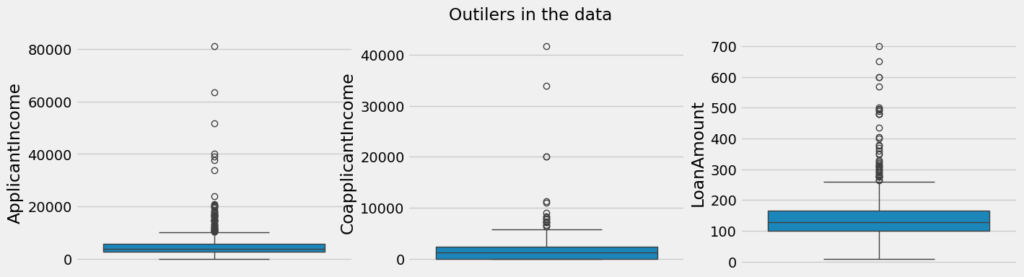
Podemos observar que existem vários valores descrepantes e como não temos informação se são frutos de erro de entrada, então vamos optar por não remove-los, mas vale ressaltar que você deve entender o motivo da existência dos dados descrepantes e avaliar manter ou não, nossa decisão é apenas didática, veja mais detallhes sobre outilers aqui.
Análise univariada
plt.rcParams['figure.figsize'] = (18, 4)
plt.subplot(1, 3, 1)
sns.histplot(data['ApplicantIncome'], color = 'green')
plt.subplot(1, 3, 2)
sns.histplot(data['CoapplicantIncome'], color = 'green')
plt.subplot(1, 3, 3)
sns.histplot(data['LoanAmount'], color = 'green')
plt.suptitle('Univariate Analysis in Numerical columns')
plt.show()
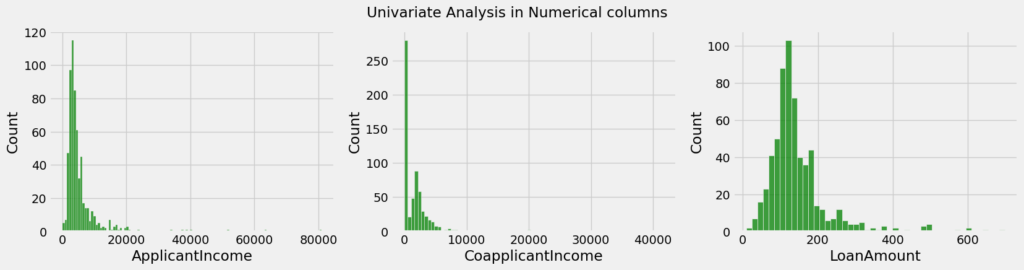
Podemos observar que essas variáveis não seguem uma destrubuição normal, então vamos realizar uma transformação log pois essa caracteristica pode adicionar uma tendência nos dados.
plt.rcParams['figure.figsize'] = (18,4)
#Aplicar a tranformação log para remoção de skewness
data['ApplicantIncome'] = np.log(data['ApplicantIncome'])
data['CoapplicantIncome'] = np.log1p(data['CoapplicantIncome'])
Visualizando após a transformação
plt.subplot(1, 2, 1)
sns.histplot(data['ApplicantIncome'], color = 'black')
plt.subplot(1, 2, 2)
sns.histplot(data['CoapplicantIncome'], color = 'black')
plt.suptitle('After log transformations')
plt.show()
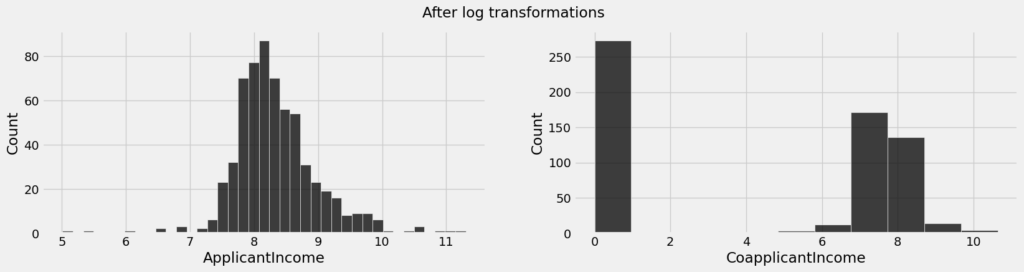
Bem melhor!
Agora vamos remover a coluna Loan_id porque ela não tem relação com a decisão de conceder ou não um empréstimo a alguém
data = data.drop(['Loan_ID'], axis = 1)
Processo de Encoding
A maioria dos algoritmos de Machine Learning, como Regressão Logística e Redes Neurais, operam apenas com números, o que exige a conversão de textos em vetores numéricos, então vamos converter algumas variáveis categóricas.
Para as variáveis que são binárias, fizemos uma simples substituição
data['Gender'] = data['Gender'].replace(('Male', 'Female'), (1, 0))
data['Married'] = data['Married'].replace(('Yes', 'No'), (1, 0))
data['Education'] = data['Education'].replace(('Graduate', 'Not Graduate'), (1, 0))
data['Self_Employed'] = data['Self_Employed'].replace(('Yes', 'No'), (1, 0))
data['Loan_Status'] = data['Loan_Status'].replace(('Y', 'N'), (1, 0))
Como sabemos que as propriedades Urban e Semi Urban tem impacto similar na aprovação dos empréstimos, então vamos aplicar o mesmo valor numérico.
data['Property_Area'] = data['Property_Area'].replace(('Urban', 'Semiurban', 'Rural'), (1, 1, 0))
Também analisamos que diferente de 0 dependentes, todas as outras quantidades tem um comportamento muito similar, então vamos aplicar o mesmo valor numérico para elas, lembrando que você pode aplicar algorítimos como o one-hot-encoder que pode fazer esse processo de forma automática.
data['Dependents'] = data['Dependents'].replace(('0', '1', '2', '3+'), (0, 1, 1, 1))
Vamos verificar se ainda existem variáveis categóricas:
data.select_dtypes('object').columns
Index([], dtype='object')Separação dos dados
Vamos separa os dados em duas bases, uma para as variáveis preditoras (X) e uma para a variável target (y)
y = data['Loan_Status']
X = data.drop(['Loan_Status'], axis = 1)
print("Shape of X: ", X.shape)
print("Shape of y: ", y.shape)
Shape of X: (614, 11)
Shape of y: (614,)Reamostragem de classes desbalanceadas
Quando trabalhamos com problemas de classificação, como a predição de aprovação de empréstimos, é comum encontrarmos datasets desbalanceados, onde uma classe (por exemplo, ‘Aprovado’) é muito mais frequente do que a outra (por exemplo, ‘Negado’). Esse desbalanceamento pode levar a um desempenho insatisfatório do modelo, pois ele tende a priorizar a classe majoritária, ignorando ou subestimando a classe minoritária.
Aplicando o SMOTE
SMOTE (Synthetic Minority Over-sampling Technique) é uma técnica popular para lidar com o desbalanceamento de classes. Em vez de simplesmente duplicar exemplos da classe minoritária (como faz a sobremostragem tradicional), o SMOTE cria novos exemplos sintéticos. Esses novos exemplos são gerados através da interpolação entre exemplos reais da classe minoritária.
from imblearn.over_sampling import SMOTE
x_resample, y_resample = SMOTE().fit_resample(X, y.values.ravel())
print("Before Resampling")
print(y.value_counts())
print("After Resampling")
y_resample = pd.DataFrame(y_resample)
print(y_resample[0].value_counts())
Before Resampling
Loan_Status
1 422
0 192
Name: count, dtype: int64
After Resampling
0
1 422
0 422Observe que antes tinhamos uma grande desbalanceamento entre as classes de status do emprestímo em conceder (1) e não conceder (0) um emprestimo. Após a aplicação do SMOTE ambas as classes tem a mesma quantidade de amostras.
Separação dos dados entre treino e teste
A separação dos dados entre treino e teste é uma etapa crucial no processo de desenvolvimento de um modelo de machine learning. Ela garante que o modelo seja capaz de generalizar bem para novos dados, evitando o problema de overfitting (quando o modelo se ajusta demais aos dados de treinamento e não consegue performar bem em dados que não viu antes).
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x_resample, y_resample, test_size = 0.2, random_state = 0)
print("Shape of x_train:", x_train.shape)
print("Shape of y_train:", y_train.shape)
print("Shape of x_test:", x_test.shape)
print("Shape of y_test:", y_test.shape)
Shape of x_train: (675, 11)
Shape of y_train: (675, 1)
Shape of x_test: (169, 11)
Shape of y_test: (169, 1)Treinamento do modelo Random Forest Classifier
O Random Forest Classifier é um modelo de machine learning baseado em um conjunto de árvores de decisão (decision trees). É uma técnica versátil usada para tarefas de classificação e regressão. O Random Forest funciona combinando o resultado de várias árvores de decisão para melhorar a precisão das previsões e evitar o overfitting.
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier(n_estimators=200)
model.fit(x_train, y_train)
Após o treinamendo do modelo, vamos realizar algumas predições nos dados de teste (x_test).
y_pred = model.predict(x_test)
print("Trainning Accuracy: ", model.score(x_train, y_train))
print("Testing Accuracy: ", model.score(x_test, y_test))
Trainning Accuracy: 1.0
Testing Accuracy: 0.8224852071005917Os resultados mostram que ao avaliar as nossas predições nos dados de treinamento (x_train) o modelo acertou todas (100%) as classificações de emprestimos, no entanto ao avaliar as predições para os dados de teste (x_teste), o modelo certou (82%) das classes de conceção de empréstimo.
Os modelos de machine learning tendem a ter uma acurácia maior nos dados de treino em relação aos dados de teste porque, durante o treinamento, o modelo ajusta seus parâmetros para se adaptar ao máximo aos padrões presentes nos dados de treino. Esse processo permite que o modelo aprenda as características específicas dos dados de treino, incluindo até mesmo ruídos e detalhes particulares.
Análise da performance do modelo
from sklearn.metrics import confusion_matrix, classification_report
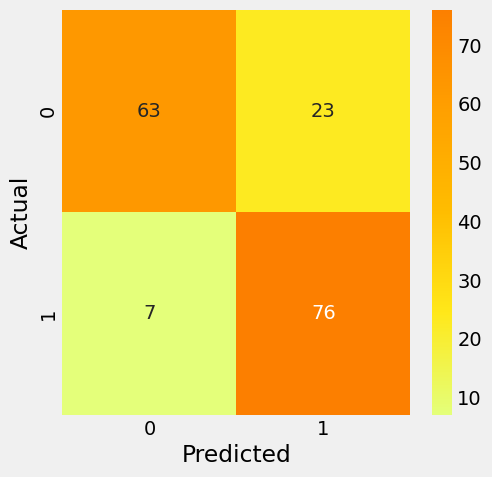
cm = confusion_matrix(y_test, y_pred)
plt.rcParams['figure.figsize'] = (5, 5)
sns.heatmap(cm, annot = True, cmap = 'Wistia', fmt = '.8g')
plt.xlabel('Predicted')
plt.ylabel('Actual')
plt.show()
# Classification reports
cr = classification_report(y_test, y_pred)
print(cr)
precision recall f1-score support
0 0.90 0.73 0.81 86
1 0.77 0.92 0.84 83
accuracy 0.82 169
macro avg 0.83 0.82 0.82 169
weighted avg 0.84 0.82 0.82 169Esse resultado mostra um bom desempenho geral do modelo, com uma acurácia de 0,82 (82%), o que indica que 82% das previsões do modelo estão corretas.
Cross Validation
Vamos aplicar o cross-validation que é uma técnica crucial em machine learning para avaliar o desempenho do modelo de maneira mais robusta e confiável. Em vez de dividir o dataset em apenas um conjunto de treino e um de teste, o cross-validation divide os dados em vários subconjuntos (folds). O modelo é treinado e testado múltiplas vezes, cada vez usando um fold diferente como conjunto de teste e os outros como conjunto de treino.
from sklearn.model_selection import cross_val_score
clf = RandomForestClassifier(random_state = 0)
scores = cross_val_score(clf, x_train, y_train, cv=5)
print(scores.mean())
0.794074074074074Salvando o modelo
Agora vamos salvar o modelo em formato pickle para que possamos utiliza-lo em nossas futuras predições com dados novos
import pickle
pickle.dump(model, open('loan_prediction.pkl', 'wb'))
Verifique se o modelo foi criado na pasta do seu projeto
Salvando a base de dados de teste para utilizar nas futuras previsões
x_test.to_csv('test.csv', index=False)
Verifique se o arquivo .csv foi criado nas pasta do seu projeto
Ao final, devemos ter uma coleção de arquivos criadas parecida com essa:
Conslusão
Neste tutorial, percorremos todas as etapas essenciais para construir um modelo de machine learning, desde a coleta e preparação dos dados até o treinamento e avaliação do modelo. O resultado é um sistema capaz de aprender os padrões dos dados históricos de concessão de empréstimos e gerar predições a partir de novos dados de forma eficiente.
Na parte 2 deste tutorial, vamos avançar ainda mais fazendo o deploy, criando uma interface interativa com o framework Streamlit. Isso permitirá que os usuários interajam diretamente com o modelo treinado, inserindo novas informações e obtendo predições de maneira prática e intuitiva.
Livros recomendados
- Mãos à obra aprendizado de máquina com Scikit-Learn, Keras & TensorFlow: conceitos, ferramentas e técnicas para a construção de sistemas inteligentes.
- Python para análise de dados
- Estatística Prática Para Cientistas de Dados: 50 Conceitos Essenciais
- Projetando Sistemas de Machine Learning
- An Introduction to Statistical Learning (Python e R)


Pingback: Criando seu primeiro projeto de machine learning com deploy: Parte 2 - IA Com Café
Pingback: Machine Learning para Equipes de TI: O Que Você Precisa Saber para Implementar com Sucesso
Pingback: Seleção e engenharia de features em machine learning - IA Com Café