Na parte 1, treinamos um modelo capaz de prever a concessão de empréstimos. Agora, é hora de transformar esse modelo em uma ferramenta útil! Neste tutorial, você aprenderá a criar uma aplicação web simples e interativa usando o Streamlit. Carregaremos o modelo treinado, construiremos uma interface para inserir novos dados e, em seguida, realizaremos novas predições. Ao final deste guia, você terá uma aplicação completa e funcional, além de uma compreensão mais profunda do processo de deploy de modelos de machine learning.
Criando a aplicação main.py
A partir desse momento vamos criar nossa aplicação python que executará a nossa interface visual com o streamlit.
1. Crie um novo arquivo no vs code chamado “main.py”
2. Importe as bibliotecas necessárias:
import streamlit as st
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import pickle
3. Vamos criar um título para a nossa aplicação no streamlit
st.title("Solicitação de Empréstimo")
st.write("### Preencha para simular sua solicitação de empréstimo!")
A partir desde momento, já podemos executar a nossa aplicação no Streamlit e observar a interface ganhando forma
No ser terminal, execute:
streamlit run main.pyEntão o streamlit irá executar o seu código python, com um título e um primeiro cabeçalho que escrevemos, ele também irá abrir uma página no browser:

4. Agora precisamos mapear as variáveis categóricas para valores numéricos que serão utilizados como entrada no nosso modelo treinado
mappings = {
'gender': {'Male': 1, 'Female': 0},
'married': {'Yes': 1, 'No': 0},
'dependents': {'0': 0, '1': 1, '2': 1, '3+': 1},
'education': {'Graduate': 1, 'Not Graduate': 0},
'self_employed': {'Yes': 1, 'No': 0},
'property_area': {'Urban': 1, 'Semi Urban': 1, 'Rural': 0}
}
5. Agora vamos criar uma função que coleta os dados de entrada que serão preenchidos em um menu lateral que será criado na tela
Cada um dos atributos aqui foram utilizados durante o treinamento, por isso precisamos definir uma valor de entrada para que posssamos realizar as predições corretamente.
Os atributos que fizemos o mapeamento anterior em “mappings”, serão utilizados em um selectbox e os demais atributos numéricos serão selecionados através de um componente slider do streamlit.
def user_input_features():
"""Função para coleta dos dados de entrada via menu lateral."""
gender = mappings['gender'][st.sidebar.selectbox("Gender", ("Male", "Female"))]
married = mappings['married'][st.sidebar.selectbox("Is Married?", ("Yes", "No"))]
dependents = mappings['dependents'][st.sidebar.selectbox("Number of Dependents", ("0", "1", "2", "3+"))]
education = mappings['education'][st.sidebar.selectbox("Education Level", ("Graduate", "Not Graduate"))]
self_employed = mappings['self_employed'][st.sidebar.selectbox("Is Self Employed?", ("Yes", "No"))]
property_area = mappings['property_area'][st.sidebar.selectbox("Property Area?", ("Urban", "Semi Urban", "Rural"))]
applicant_income = st.sidebar.slider("Applicant Income?", 5000, 10000, 8000) / 1000
coapplicant_income = st.sidebar.slider("Co Applicant Income?", 0, 10000, 4000) / 1000
loan_amount = st.sidebar.slider("Loan Amount", 10, 400, 200)
loan_amount_term = st.sidebar.slider("Loan Amount Term", 12, 480, 300)
credit_history = st.sidebar.slider("Credit History", 0, 1, 1)
data = {
'Gender': gender,
'Married': married,
'Dependents': dependents,
'Education': education,
'Self_Employed': self_employed,
'ApplicantIncome': applicant_income,
'CoapplicantIncome': coapplicant_income,
'LoanAmount': loan_amount,
'Loan_Amount_Term': loan_amount_term,
'Credit_History': credit_history,
'Property_Area': property_area,
}
return pd.DataFrame(data, index=[0])
Ao final, retornaremos um dataframe do pandas com as seleções do usuário que serão utilizadas como entrada para nossas predições no modelo previamente treinado.
6. Agora vamos criar uma função para carregar o modelo (loan_prediction.pkl) que treinamos no tutorial 1:
def load_model(filename='loan_prediction.pkl'):
"""Função para carregar o modelo salvo."""
# Abre o arquivo pickle e carrega o modelo treinado
with open(filename, 'rb') as file:
return pickle.load(file)
7. Vamos criar uma função para realizar a previsão e obter as probabilidades
def predict_loan_approval(model, features):
"""Função para realizar a previsão e obter probabilidades."""
# Realiza a previsão com base nas características do usuário
prediction = model.predict(features)
# Obtém as probabilidades associadas à previsão
prediction_probability = model.predict_proba(features)
return prediction, prediction_probability
8. Vamos criar o método main do nosso código para executar as funções e carregar os componentes do streamlit
if __name__ == "__main__":
9. Dentro do método main, vamos carregar os dados de entrada do usuário e fazer uma concatenação com os dados de teste (teste.csv) que criamos no tutorial anterior
if __name__ == "__main__":
input_df = user_input_features()
# Carregando o dataset de teste e concatenando com os dados do usuário
promotion_test = pd.read_csv('test.csv')
df = pd.concat([input_df, promotion_test], axis=0).head(1)
10. Agora chamamos a função que carrega o modelo e realizamos a previsão baseada nos nossos dados de entrada, teremos duas saídas:
prediction: previsão binária feita pelo modelo (0: não será aprovado, 1: será aprovado)
prediction_probability: matriz que contém as probabilidades associadas a cada possível classe de saída (0 ou 1)
if __name__ == "__main__":
input_df = user_input_features()
# Carregando o dataset de teste e concatenando com os dados do usuário
promotion_test = pd.read_csv('test.csv')
df = pd.concat([input_df, promotion_test], axis=0).head(1)
# Carregando o modelo e realizando a previsão
model = load_model()
prediction, prediction_probability = predict_loan_approval(model, df)
11. Então vamos exibir uma mensagem na tela com o resultado da simulação de empréstimo.
if __name__ == "__main__":
input_df = user_input_features()
# Carregando o dataset de teste e concatenando com os dados do usuário
promotion_test = pd.read_csv('test.csv')
df = pd.concat([input_df, promotion_test], axis=0).head(1)
# Carregando o modelo e realizando a previsão
model = load_model()
prediction, prediction_probability = predict_loan_approval(model, df)
# Resultados
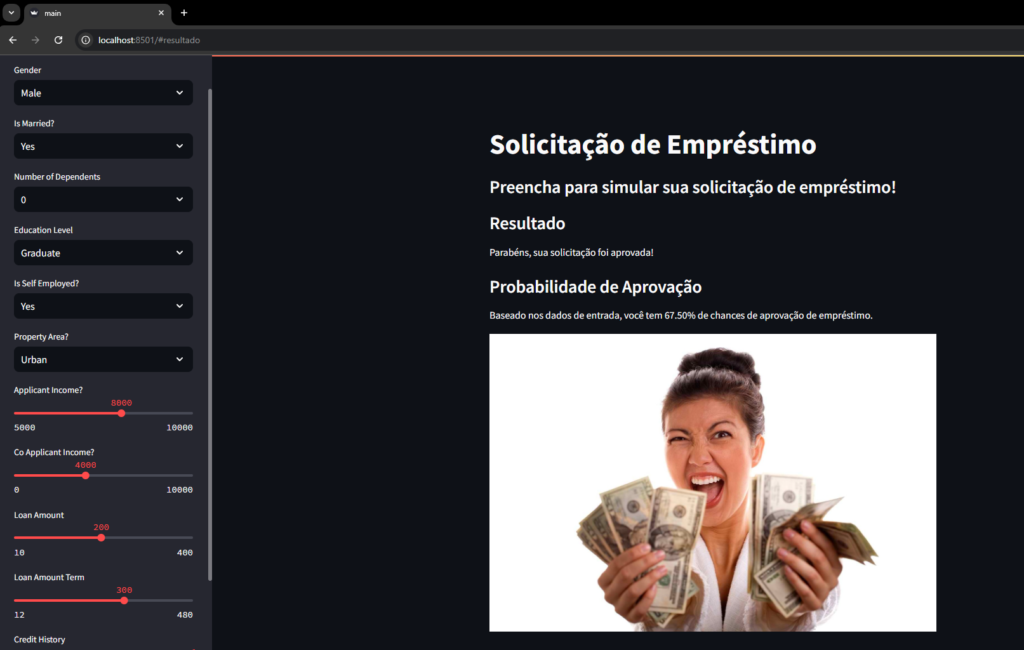
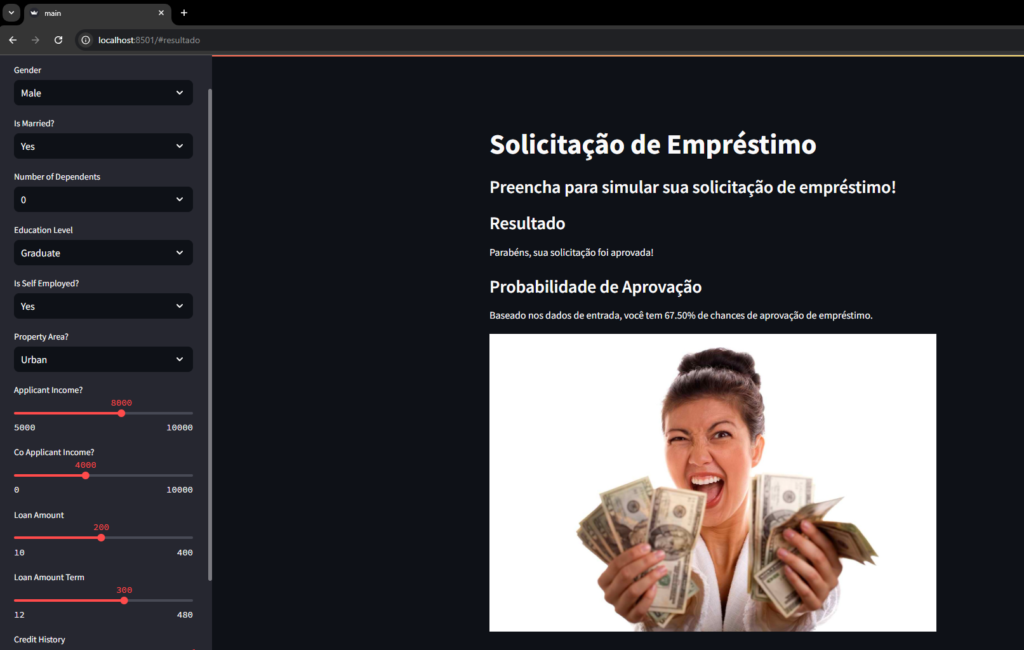
st.subheader('Resultado')
result_message = ['Desculpe, não podemos lhe conceder um empréstimo!', 'Parabéns, sua solicitação foi aprovada!']
st.write(result_message[prediction[0]])
st.subheader('Probabilidade de Aprovação')
st.write(f'Baseado nos dados de entrada, você tem {prediction_probability[0][1] * 100:.2f}% de chances de aprovação de empréstimo.')
Caso a predição retorne 0, então a mensagem será: “Desculpe, não podemos lhe conceder um empréstimo!”
Caso a predição retorne 1, então a mensagem será: “Parabéns, sua solicitação foi aprovada!'”
Também exibiremos a probabilidade da concessão do empréstimo.
12. Ao final, utilizaremos duas imagens para ilustrar a aprovação ou não aprovação do empréstimo, essas imagens colocadas dentro de uma pasta chamada “images” no repositório principal do projeto.
Ao final esse será o código completo:
import streamlit as st
import numpy as np
import pandas as pd
import pickle
import matplotlib.pyplot as plt
# Configuração inicial
st.title("Solicitação de Empréstimo")
st.write("### Preencha para simular sua solicitação de empréstimo!")
# Mapeamentos
mappings = {
'gender': {'Male': 1, 'Female': 0},
'married': {'Yes': 1, 'No': 0},
'dependents': {'0': 0, '1': 1, '2': 1, '3+': 1},
'education': {'Graduate': 1, 'Not Graduate': 0},
'self_employed': {'Yes': 1, 'No': 0},
'property_area': {'Urban': 1, 'Semi Urban': 1, 'Rural': 0}
}
def user_input_features():
"""Função para coleta dos dados de entrada via menu lateral."""
gender = mappings['gender'][st.sidebar.selectbox("Gender", ("Male", "Female"))]
married = mappings['married'][st.sidebar.selectbox("Is Married?", ("Yes", "No"))]
dependents = mappings['dependents'][st.sidebar.selectbox("Number of Dependents", ("0", "1", "2", "3+"))]
education = mappings['education'][st.sidebar.selectbox("Education Level", ("Graduate", "Not Graduate"))]
self_employed = mappings['self_employed'][st.sidebar.selectbox("Is Self Employed?", ("Yes", "No"))]
property_area = mappings['property_area'][st.sidebar.selectbox("Property Area?", ("Urban", "Semi Urban", "Rural"))]
applicant_income = st.sidebar.slider("Applicant Income?", 5000, 10000, 8000) / 1000
coapplicant_income = st.sidebar.slider("Co Applicant Income?", 0, 10000, 4000) / 1000
loan_amount = st.sidebar.slider("Loan Amount", 10, 400, 200)
loan_amount_term = st.sidebar.slider("Loan Amount Term", 12, 480, 300)
credit_history = st.sidebar.slider("Credit History", 0, 1, 1)
data = {
'Gender': gender,
'Married': married,
'Dependents': dependents,
'Education': education,
'Self_Employed': self_employed,
'ApplicantIncome': applicant_income,
'CoapplicantIncome': coapplicant_income,
'LoanAmount': loan_amount,
'Loan_Amount_Term': loan_amount_term,
'Credit_History': credit_history,
'Property_Area': property_area,
}
return pd.DataFrame(data, index=[0])
def load_model(filename='loan_prediction.pkl'):
"""Função para carregar o modelo salvo."""
with open(filename, 'rb') as file:
return pickle.load(file)
def predict_loan_approval(model, features):
"""Função para realizar a previsão e obter probabilidades."""
prediction = model.predict(features)
prediction_probability = model.predict_proba(features)
return prediction, prediction_probability
if __name__ == "__main__":
# Fluxo principal
input_df = user_input_features()
# Carregando o dataset de teste e concatenando com os dados do usuário
promotion_test = pd.read_csv('test.csv')
df = pd.concat([input_df, promotion_test], axis=0).head(1)
# Carregando o modelo e realizando a previsão
model = load_model()
prediction, prediction_probability = predict_loan_approval(model, df)
# Resultados
st.subheader('Resultado')
result_message = ['Desculpe, não podemos lhe conceder um empréstimo!', 'Parabéns, sua solicitação foi aprovada!']
st.write(result_message[prediction[0]])
st.subheader('Probabilidade de Aprovação')
st.write(f'Baseado nos dados de entrada, você tem {prediction_probability[0][1] * 100:.2f}% de chances de aprovação de empréstimo.')
# Exibindo imagem de acordo com a previsão
image = './images/cash_ok.jpg' if prediction == 1 else './images/no_money.jpg'
st.image(image, use_column_width=True)
Então finalmente você pode acessar a tela no browser que você acessou no passo 3 e utilizar o menu lateral para simular as entradas do usuário que como: Gênero, Salário, Valor de empréstimo e então observar como elas influenciam o resultado final da predição e suas probabilidades.
Conclusão
Na segunda parte do nosso tutorial, você aprendeu a desenvolver uma aplicação interativa usando Streamlit para simular solicitações de empréstimo. Exploramos passo a passo como construir uma interface amigável que coleta os dados do usuário, faz previsões utilizando um modelo de machine learning treinado, e exibe os resultados de forma clara e acessível.
Neste estágio, você não apenas integrou o modelo de machine learning à aplicação, mas também aprendeu a manipular os dados de entrada, mapear variáveis categóricas para numéricas, e apresentar a previsão ao usuário com informações adicionais, como a probabilidade de aprovação.
Este projeto é uma excelente introdução ao machine learning aplicado, demonstrando como transformar um modelo treinado em um produto utilizável para resolver problemas reais. Ao implementar uma interface de usuário intuitiva e utilizar um modelo preditivo, você deu um grande passo para dominar a implementação prática de projetos de inteligência artificial.
No próximo passo, você pode explorar como melhorar a precisão do seu modelo, adicionar funcionalidades extras à interface, ou mesmo implementar novos tipos de modelos para diferentes aplicações. O importante é continuar experimentando e aprendendo, pois a prática é o que solidifica o conhecimento.
Livros recomendados: Recomendações