A regularização é uma técnica essencial em machine learning para melhorar a performance dos modelos e evitar o overfitting. Neste artigo, vamos explorar as principais técnicas de regularização, como L1, L2, Dropout e Batch Normalization, e entender seus benefícios para criar modelos mais robustos e generalizáveis.

Regularização é um conjunto de métodos usados para induzir simplicidade nos modelos de machine learning, adicionando uma penalidade às suas complexidades. O objetivo é prevenir o overfitting, onde o modelo se ajusta demais aos dados de treinamento e perde a capacidade de generalizar para novos dados.
Técnicas de Regularização

Regularização L1 (Lasso)
A regularização L1 adiciona uma penalidade proporcional à soma dos valores absolutos dos coeficientes. Isso tende a produzir modelos esparsos, onde alguns coeficientes são exatamente zero, eliminando características irrelevantes.
A chave da L1 está na forma da penalidade. Ao adicionar a soma dos valores absolutos dos coeficientes à função de custo, a otimização do modelo é direcionada para soluções onde muitos coeficientes se tornam exatamente zero. Isso ocorre porque a norma L1 (valor absoluto) tem “cantos” que incentivam o modelo a “colar” nos eixos, fazendo com que alguns coeficientes sejam anulados.
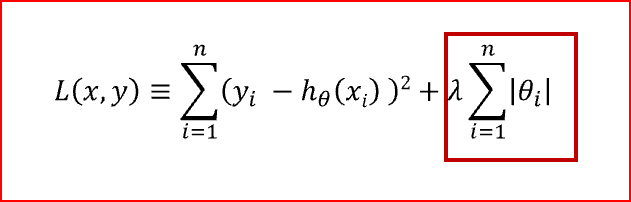
- A regularização L1 pode reduzir alguns coeficientes a zero, eliminando features irrelevantes e realizando uma seleção automática de features. Isso pode simplificar o modelo e melhorar a interpretabilidade.
- Como outras técnicas de regularização, a L1 ajuda a prevenir overfitting ao adicionar uma penalidade à complexidade do modelo, forçando-o a generalizar melhor e evitar ajustes excessivos aos dados de treinamento.
- Ao eliminar features irrelevantes, a regularização L1 torna o modelo mais fácil de interpretar, pois destaca as features mais importantes para a previsão.
- A regularização L1 reduz a variância do modelo, tornando-o menos sensível a pequenas variações nos dados de treinamento.
Regularização L2 (Ridge)
A regularização L2 adiciona uma penalidade à função de custo do modelo, proporcional à soma dos quadrados dos coeficientes dos parâmetros do modelo. Esta penalidade força os coeficientes a serem pequenos, mas não necessariamente a zero, o que ajuda a manter todos os coeficientes envolvidos na previsão.

- A regularização L2 ajuda a reduzir o overfitting ao penalizar coeficientes grandes, tornando o modelo menos complexo e mais generalizável para novos dados.
- Ao forçar os coeficientes a serem pequenos, a regularização L2 torna o modelo mais estável e menos sensível a pequenas variações nos dados de treinamento.
- Diferente da regularização L1, que tende a zerar coeficientes, a regularização L2 mantém todos os coeficientes não nulos. Isso é útil quando todas as features têm alguma importância na previsão.
- A regularização L2 é computacionalmente eficiente e fácil de implementar, tornando-a uma escolha popular para grandes datasets.
| Característica | L1 (Lasso) | L2 (Ridge) |
| Penalidade | Soma dos valores absolutos | Soma dos quadrados dos valores |
| Efeito nos coeficientes | Muitos coeficientes se tornam zero | Todos os coeficientes são encolhidos, mas raramente se tornam zero |
| Interpretabilidade | Alta | Média |
| Seleção de features | Sim | Não (embora possa reduzir a importância de features menos relevantes) Exportar para as Planilhas |
Elastic Net
O Elastic Net combina as vantagens do Lasso e do Ridge, aplicando uma penalização que é uma combinação linear das normas L1 e L2. Isso permite controlar o grau de sparsidade e encolhimento dos coeficientes, oferecendo maior flexibilidade.
É útil quando há muitas features correlacionadas, pois pode selecionar grupos de features correlacionadas.
Dropout
Dropout é uma técnica de regularização usada em redes neurais, onde, durante o treinamento, unidades da rede são “desligadas” aleatoriamente com uma certa probabilidade. Isso força a rede a aprender representações redundantes, tornando o modelo mais robusto.

Durante o treinamento de uma rede neural, o Dropout desativa aleatoriamente uma fração das unidades (neurônios) em cada camada com uma certa probabilidade p (geralmente entre 0.2 e 0.5). Isso significa que em cada passo do treinamento, a estrutura da rede muda ligeiramente, pois diferentes subconjuntos de neurônios são ignorados.
- Ao desativar aleatoriamente neurônios durante o treinamento, o Dropout previne que a rede se torne excessivamente dependente de unidades específicas, forçando-a a aprender representações mais robustas e generalizáveis.
- O Dropout pode ser visto como a combinação de muitas redes neurais diferentes (uma rede para cada subconjunto de unidades). Durante a inferência, todas essas “redes” são combinadas, resultando em uma abordagem similar a um ensemble, que geralmente apresenta melhor desempenho do que redes individuais.
- O Dropout é fácil de implementar e computacionalmente eficiente, pois apenas envolve a aplicação de uma máscara binária durante o treinamento.
- Em combinação com outras técnicas de regularização (como L2), o Dropout pode proporcionar melhorias adicionais no desempenho da rede.
Early Stopping
Early Stopping é uma técnica de regularização utilizada em machine learning e deep learning para prevenir o overfitting e melhorar a generalização dos modelos. Ela envolve monitorar a performance do modelo em um conjunto de validação durante o treinamento e parar o treinamento quando o desempenho no conjunto de validação começar a piorar.

O Early Stopping monitora uma métrica de desempenho (geralmente a perda ou a acurácia) no conjunto de validação ao final de cada época de treinamento. Se a métrica de desempenho parar de melhorar após um certo número de épocas consecutivas (conhecido como “paciente”), o treinamento é interrompido. O modelo é então restaurado para o ponto onde ele apresentou o melhor desempenho no conjunto de validação.
- O Early Stopping previne o overfitting ao parar o treinamento antes que o modelo comece a se ajustar demais aos dados de treinamento, o que pode degradar a performance em novos dados.
- Ao interromper o treinamento assim que a performance do modelo começa a piorar no conjunto de validação, o Early Stopping economiza tempo e recursos computacionais.
- Modelos treinados com Early Stopping tendem a generalizar melhor para novos dados, pois evitam o ajuste excessivo aos dados de treinamento.
- O Early Stopping é simples de implementar e não requer ajustes complexos, tornando-o uma técnica prática e eficiente.
Batch Normalization
Batch Normalization é uma técnica utilizada em deep learning para acelerar o treinamento das redes neurais e melhorar a estabilidade. Introduzida por Sergey Ioffe e Christian Szegedy em 2015, essa técnica normaliza as ativações de cada camada para ter média zero e variância unitária. Além disso, adiciona dois parâmetros treináveis que permitem que a rede recupere a capacidade representacional se necessário.

A Normalização por Batches funciona como um estabilizador em redes neurais profundas. Ela normaliza as ativações de cada neurônio dentro de um mini-batch, garantindo que os dados que entram na próxima camada estejam em uma escala similar. Isso facilita o aprendizado da rede e melhora sua performance.
- Estabilização do treinamento: Reduz a sensibilidade da rede a mudanças nos parâmetros e à inicialização de pesos.
- Aceleração da convergência: Permite o uso de taxas de aprendizado mais altas.
- Regularização: Atua como uma forma de regularização, reduzindo o overfitting.
- Covariante shift: Ajuda a reduzir o covariante shift, ou seja, a mudança na distribuição das ativações ao longo do treinamento.
Conclusão
A regularização é indispensável para melhorar a robustez e a generalização dos modelos de machine learning. Ao aplicar técnicas como L1, L2, Dropout, Early Stopping e Batch Normalization, você pode criar modelos que não apenas performam bem em dados de treinamento, mas também se generalizam efetivamente para novos dados. Entender e implementar regularização tratá um grande diferencial para o resultado dos seus modelos e para seus conhecimentos em machine learning.
Leitura Adicional
Regularização com sklearn
Regularização dropout em deep learning
Batch Normalization em CNN
Recomendação de Livros
- Mãos à obra aprendizado de máquina com Scikit-Learn, Keras & TensorFlow: conceitos, ferramentas e técnicas para a construção de sistemas inteligentes.
- Python para análise de dados
- Estatística Prática Para Cientistas de Dados: 50 Conceitos Essenciais
- An Introduction to Statistical Learning (Python e R)