A preparação dos dados é um dos fatores mais importantes para o sucesso de qualquer projeto de machine learning. Mesmo os algoritmos mais avançados podem falhar se os dados utilizados forem inconsistentes, incompletos ou mal preparados, modelos poderosos não podem compensar dados ruins, e uma preparação adequada pode melhorar significativamente o desempenho e a precisão. Neste post, vamos explorar 5 dicas práticas para melhorar a preparação dos seus dados e garantir que seu modelo tenha as melhores chances de sucesso.

Introdução: Por que a preparação dos dados é importante?
Em Machine Learning, o modelo é tão bom quanto os dados que o alimentam. Dados de baixa qualidade podem levar a previsões imprecisas, overfitting, ou até mesmo a conclusões equivocadas. Por isso, dedicar tempo à limpeza, organização e preparação dos dados é essencial para garantir que o modelo aprenda padrões reais e generalize bem para novos dados.
1. Remova dados duplicados
Dados duplicados podem distorcer a análise e o treinamento do modelo, levando a resultados enviesados. A remoção de duplicatas ajuda a garantir que cada observação seja única e contribua de forma equilibrada para o aprendizado do modelo.
- Impacto: Melhora a performance e a precisão do modelo.
- Como fazer: Utilize funções como
drop_duplicates()no Pandas para identificar e remover duplicatas.
import pandas as pd
# Exemplo de remoção de duplicatas
df = pd.DataFrame(
{
'Nome': ['Ana', 'Carlos', 'Ana'],
'Idade': [25, 30, 25]}
)
df_new = df.drop_duplicates()
print(f'Antes :{df}')
print(f'Depois :{df_new}')
Antes :
Nome Idade
0 Ana 25
1 Carlos 30
2 Ana 25
Depois :
Nome Idade
0 Ana 25
1 Carlos 302. Tratamento de valores faltantes
Valores faltantes são comuns em datasets reais e podem prejudicar o treinamento do modelo, eles comprometem o aprendizado e podem introduzir viés se não tratados adequadamente. Existem várias técnicas para lidar com esse problema, como preenchimento por média, mediana, moda ou até mesmo a remoção de registros incompletos.
Métodos simples:
- Preenchimento por média:
df['coluna'].fillna(df['coluna'].mean()) - Preenchimento por moda:
df['coluna'].fillna(df['coluna'].mode()[0]) - Remoção de registros:
df.dropna()
Preenchimento com média o moda:
# Preenchendo valores ausentes com a média
df['Idade'] = df['Idade'].fillna(df['Idade'].mean())
Remoção de linhas/colunas com muitos valores ausentes:
# Removendo linhas com valores ausentes
df = df.dropna()
3. Normalização e Padronização
Normalização e padronização são técnicas usadas para ajustar a escala dos dados, especialmente quando as features têm magnitudes diferentes. A normalização escala os valores para um intervalo (geralmente [0, 1]), enquanto a padronização transforma os dados para ter média 0 e desvio padrão 1.
Se suas features têm escalas diferentes (como renda em milhares e idade em dezenas), modelos sensíveis a escala, como SVM ou KNN, podem ter dificuldades.
Quando usar:
- Normalização: útil para algoritmos sensíveis à escala, como redes neurais.
- Padronização: ideal para métodos que assumem distribuição normal, como regressão linear.
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
df['Idade_normalizada'] = scaler.fit_transform(df[['Idade']])
Nome Idade Idade_normalizada
0 Ana 25 0.0
1 Carlos 30 1.04. Identificação e remoção de outliers
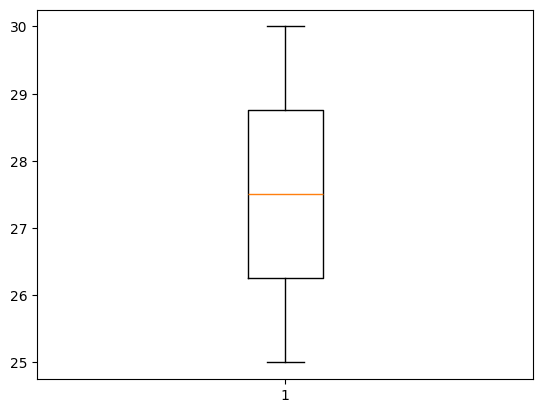
Outliers são valores extremos que se desviam significativamente do padrão e que podem distorcer o modelo. Eles podem ser identificados usando gráficos (como boxplots) ou métodos estatísticos (como o Z-score ou IQR).
- Estratégias rápidas:
- Boxplot: Visualize outliers com
sns.boxplot(). - Z-score: Remova pontos com Z-score maior que 3 ou menor que -3.
- IQR: Calcule o intervalo interquartil e remova valores fora de 1,5 * IQ
- Boxplot: Visualize outliers com
Boxplot:
import matplotlib.pyplot as plt
plt.boxplot(df['Idade'])
plt.show()
Quando devo remover outliers?
Devo remover outliers quando eles são claramente ruídos, erros de medição ou dados inconsistentes que não representam a realidade do problema, podendo distorcer o modelo e prejudicar sua performance. Isso é especialmente útil em cenários onde os outliers não têm significado relevante e sua presença afeta métricas como média e desvio padrão, ou quando o dataset é grande o suficiente para que sua remoção não impacte negativamente a quantidade de dados disponíveis para treinamento.
Remoção de outliers com base no IQR:
Q1 = df['Idade'].quantile(0.25)
Q3 = df['Idade'].quantile(0.75)
IQR = Q3 - Q1
df = df[~((df['Idade'] < (Q1 - 1.5 * IQR)) | (df['Idade'] > (Q3 + 1.5 * IQR)))]
Quando NÃO devo remover outliers?
Não devo remover outliers quando eles representam informações valiosas ou são parte natural dos dados, como em casos de detecção de anomalias (fraudes, falhas, doenças raras), distribuições com caudas longas (renda, preços de ações) ou quando são eventos legítimos, ainda que raros. Além disso, em datasets pequenos, a remoção pode reduzir excessivamente o número de amostras, prejudicando o modelo. Antes de remover, é essencial investigar se os outliers são erros de medição ou coleta, pois a correção pode ser mais adequada do que a exclusão.
5. Balanceamento de classes
Em problemas de classificação, datasets desbalanceados podem levar a modelos tendenciosos, que priorizam a classe majoritária. Técnicas como oversampling (aumentar a classe minoritária) e undersampling (reduzir a classe majoritária) ajudam a equilibrar o dataset.
Se você está trabalhando com classificação e uma classe domina o dataset, o modelo pode ficar enviesado. Exemplo:
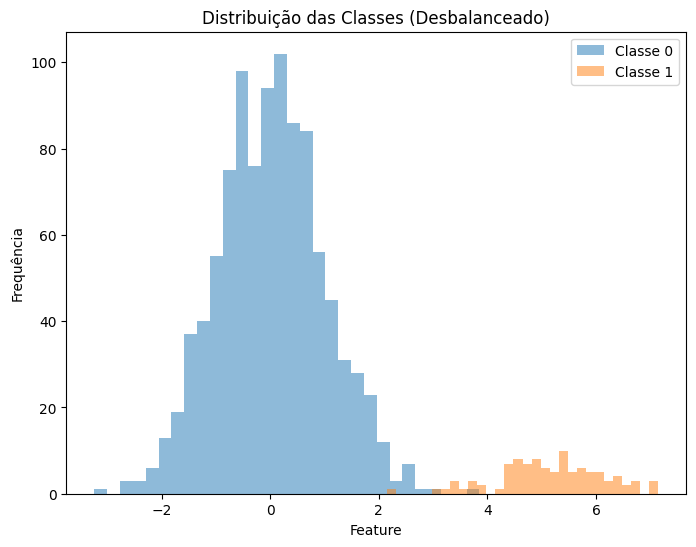
Oversampling (SMOTE)
Ele funciona criando exemplos sintéticos para a classe minoritária, em vez de simplesmente replicar instâncias existentes. Esses exemplos são gerados interpolando os valores de features entre os dados existentes da classe minoritária, aumentando sua representatividade sem introduzir duplicatas
import matplotlib.pyplot as plt
import numpy as np
from imblearn.over_sampling import SMOTE
# Aplicando o SMOTE para oversampling
smote = SMOTE(random_state=42)
X_resampled, y_resampled = smote.fit_resample(df[['feature']], df['target'])
df_resampled = pd.DataFrame({'feature': X_resampled.values.ravel(), 'target': y_resampled})
# Plotando a distribuição das classes após o SMOTE
plt.figure(figsize=(8, 6))
plt.hist(df_resampled[df_resampled['target'] == 0]['feature'], bins=30, alpha=0.5, label='Classe 0')
plt.hist(df_resampled[df_resampled['target'] == 1]['feature'], bins=30, alpha=0.5, label='Classe 1')
plt.xlabel('Feature')
plt.ylabel('Frequência')
plt.title('Distribuição das Classes (Após SMOTE)')
plt.legend()
plt.show()
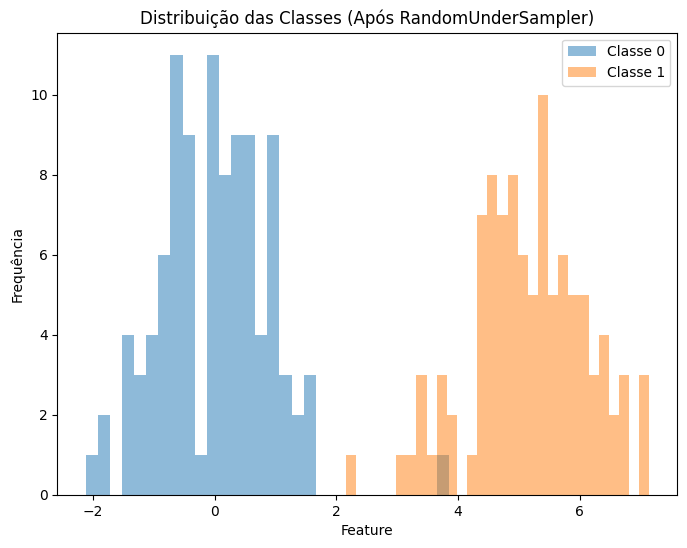
Undersampling (RandomUnderSampler)
Em vez de criar novos exemplos para a classe minoritária, como no oversampling, o undersampling remove instâncias da classe dominante para equilibrar a proporção entre as classes. Essa abordagem é útil em datasets grandes, onde a classe majoritária contém muitos exemplos redundantes que não adicionam valor ao aprendizado do modelo.
from imblearn.under_sampling import RandomUnderSampler
# Aplicando o RandomUnderSampler para undersampling
rus = RandomUnderSampler(random_state=42)
X_resampled, y_resampled = rus.fit_resample(df[['feature']], df['target'])
df_resampled = pd.DataFrame({'feature': X_resampled.values.ravel(), 'target': y_resampled})
# Plotando a distribuição das classes após o RandomUnderSampler
plt.figure(figsize=(8, 6))
plt.hist(df_resampled[df_resampled['target'] == 0]['feature'], bins=30, alpha=0.5, label='Classe 0')
plt.hist(df_resampled[df_resampled['target'] == 1]['feature'], bins=30, alpha=0.5, label='Classe 1')
plt.xlabel('Feature')
plt.ylabel('Frequência')
plt.title('Distribuição das Classes (Após RandomUnderSampler)')
plt.legend()
plt.show()
Conclusão
A preparação dos dados é uma etapa crítica em qualquer projeto de Machine Learning. Ao seguir essas dicas práticas, você pode garantir que seus dados estejam limpos, organizados e prontos para alimentar modelos robustos e precisos. Lembre-se: um bom modelo começa com bons dados. Portanto, invista tempo na revisão e preparação dos seus datasets antes de partir para o treinamento.
Se você gostou dessas dicas, compartilhe este blog e deixe seu comentário abaixo! E não se esqueça de explorar outras técnicas avançadas de pré-processamento para elevar ainda mais a qualidade dos seus projetos de ML.
Recomendação de livros
- Mãos à obra aprendizado de máquina com Scikit-Learn, Keras & TensorFlow: conceitos, ferramentas e técnicas para a construção de sistemas inteligentes.
- Python para análise de dados
- An Introduction to Statistical Learning (Python e R)