
No universo do aprendizado de máquina (machine learning), existem diversas abordagens para ensinar máquinas a aprender com dados. Duas das principais metodologias são o aprendizado baseado em instâncias e o aprendizado baseado em modelos. Embora ambas tenham o mesmo objetivo — fazer previsões ou tomar decisões com base em dados —, elas funcionam de maneiras bastante diferentes. Vamos explorar essas diferenças e entender quando cada uma é mais adequada

O que é aprendizado baseado em instâncias?
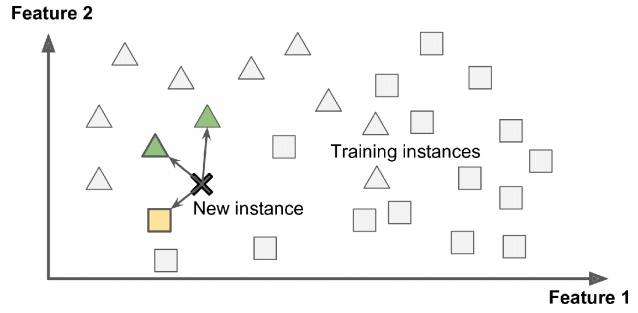
No aprendizado baseado em instâncias, também conhecido como Instance-Based Learning (IBL), o algoritmo não cria um modelo explícito a partir dos dados de treinamento. Em vez disso, ele armazena as instâncias (ou exemplos) do conjunto de dados e faz previsões com base na similaridade entre novas entradas e as instâncias armazenadas. Esse método é conhecido por ser “preguiçoso”, pois o processamento ocorre apenas no momento da previsão, e não durante o treinamento.
Características principais:
- Memoriza os dados: Armazena todas ou a maioria das instâncias de treinamento.
- Flexível: É fácil de atualizar com novos dados.
- Previsões locais: Calcula as respostas com base em instâncias próximas da entrada fornecida.
Exemplos de algoritmos:
- K-Nearest Neighbors (KNN): Um dos métodos mais populares, o KNN classifica novos dados com base nos “k” vizinhos mais próximos no espaço de características.
- Sistemas de recomendação baseados em similaridade: Muitas plataformas de streaming ou e-commerce usam essa abordagem para sugerir produtos ou conteúdos semelhantes aos que o usuário já consumiu.
Vantagens:
- Simplicidade: Não requer um processo complexo de treinamento.
- Adaptabilidade: Pode se ajustar a novos dados sem a necessidade de retreinamento.
- Interpretabilidade: É fácil entender como as previsões são feitas.
Desvantagens:
- Custo computacional: Pode ser lento para grandes volumes de dados, pois compara cada nova instância com todo o conjunto de treinamento.
- Sensibilidade a ruídos: Dados inconsistentes ou irrelevantes podem prejudicar a precisão.
O que é aprendizado baseado em modelos?
Já no aprendizado baseado em modelos, ou Model-Based Learning, o algoritmo cria um modelo matemático durante a fase de treinamento, que captura padrões e relações nos dados e busca encontrar uma representação generalizada. Esse modelo é então usado para fazer previsões em novos dados. Diferente do aprendizado baseado em instâncias, essa abordagem é “eager” (ansiosa), pois o processamento ocorre principalmente durante o treinamento.

Características principais:
- Desempenho escalável: Geralmente, é mais eficiente para previsões com grandes conjuntos de dados.
- Generaliza os dados: Encontra padrões gerais que podem ser aplicados a novos exemplos.
- Requer treinamento inicial: O modelo precisa ser treinado antes de fazer previsões.
Exemplos de algoritmos:
- Regressão Linear: Um modelo que aprende uma relação linear entre as variáveis de entrada e a saída.
- Árvores de Decisão e Random Forest: Modelos que criam regras de decisão com base nos dados de treinamento.
- Redes Neurais: Modelos complexos que simulam o funcionamento do cérebro humano para aprender padrões não lineares.
Vantagens:
- Eficiência: Após o treinamento, fazer previsões é rápido, pois o modelo já está pronto.
- Escalabilidade: Lida melhor com grandes volumes de dados.
- Generalização: Pode capturar padrões complexos e generalizar bem para novos dados.
Desvantagens:
- Complexidade: Requer um processo de treinamento mais elaborado.
- Overfitting: Se não for bem ajustado, o modelo pode se adaptar demais aos dados de treinamento, perdendo a capacidade de generalização.
- Interpretabilidade: Alguns modelos, como redes neurais profundas, são difíceis de interpretar.
Comparativo entre as abordagens
| Característica | Baseado em Instâncias | Baseado em Modelos |
|---|---|---|
| Complexidade do treinamento | Baixa | Alta |
| Complexidade da previsão | Alta | Baixa |
| Memoriza dados de treinamento? | Sim | Não |
| Generaliza os dados? | Não | Sim |
| Exemplo | KNN | Regressão Linear, Redes Neurais |
Quando usar cada abordagem?

A escolha entre aprendizado baseado em instâncias e baseado em modelos depende do problema que você está tentando resolver e das características dos seus dados:
- Use aprendizado baseado em instâncias quando:
- O conjunto de dados é pequeno ou médio.
- A interpretabilidade é importante.
- Os dados têm uma estrutura complexa, mas localmente consistente.
- Use aprendizado baseado em modelos quando:
- O conjunto de dados é grande.
- A eficiência na previsão é crítica.
- Você precisa capturar padrões globais e generalizar para novos dados.
Implementações em Python
Exemplos simples de como implementar as duas abordagens em Python usando bibliotecas populares como scikit-learn.
KNN: Baseado em Instâncias
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score
# Carregar o dataset
iris = load_iris()
X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.3, random_state=42)
# Treinar o modelo KNN
knn = KNeighborsClassifier(n_neighbors=3)
knn.fit(X_train, y_train)
# Fazer previsão
y_pred = knn.predict(X_test)
print(f"Acurácia do KNN: {accuracy_score(y_test, y_pred):.2f}")
Acurácia do KNN: 1.00Regressão Linear: Baseado em Modelos
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
# Dados de exemplo
X = [[1], [2], [3], [4], [5]]
y = [1.5, 3.2, 4.8, 6.1, 7.4]
# Treinar o modelo
model = LinearRegression()
model.fit(X, y)
# Fazer previsão
predictions = model.predict(X)
mse = mean_squared_error(y, predictions)
print(f"Erro quadrático médio (MSE): {mse:.2f}")
Erro quadrático médio (MSE): 0.02Conclusão
Ambas as abordagens têm seus pontos fortes e fracos, e a escolha certa depende do contexto do problema. Enquanto o aprendizado baseado em instâncias é mais simples e adaptável, o aprendizado baseado em modelos oferece maior eficiência e capacidade de generalização. Entender essas diferenças é essencial para aplicar a técnica certa e obter os melhores resultados em seus projetos de Machine Learning.
Gostou do conteúdo? Compartilhe e deixe suas perguntas nos comentários!
Recomendação de livros
- Mãos à obra aprendizado de máquina com Scikit-Learn, Keras & TensorFlow: conceitos, ferramentas e técnicas para a construção de sistemas inteligentes.
- Python para análise de dados
- Estatística Prática Para Cientistas de Dados: 50 Conceitos Essenciais
- An Introduction to Statistical Learning (Python e R)



