
Random Forest, ou Floresta Aleatória, é um dos algoritmos de aprendizado de máquina mais populares e versáteis. Ele é amplamente utilizado para tarefas de classificação e regressão, graças à sua capacidade de lidar com grandes volumes de dados, evitar overfitting e fornecer resultados robustos. Neste post, vamos construir um Random Forest do zero em Python, compreendendo sua teoria e implementando suas principais funções passo a passo.

O que é Random Forest?
Random Forest é um método de ensemble learning que combina várias árvores de decisão para criar um modelo mais robusto e preciso. A ideia básica é treinar múltiplas árvores de decisão em subconjuntos aleatórios dos dados e, em seguida, combinar suas previsões para obter um resultado final. Esse processo ajuda a reduzir a variância e a melhorar a generalização do modelo.
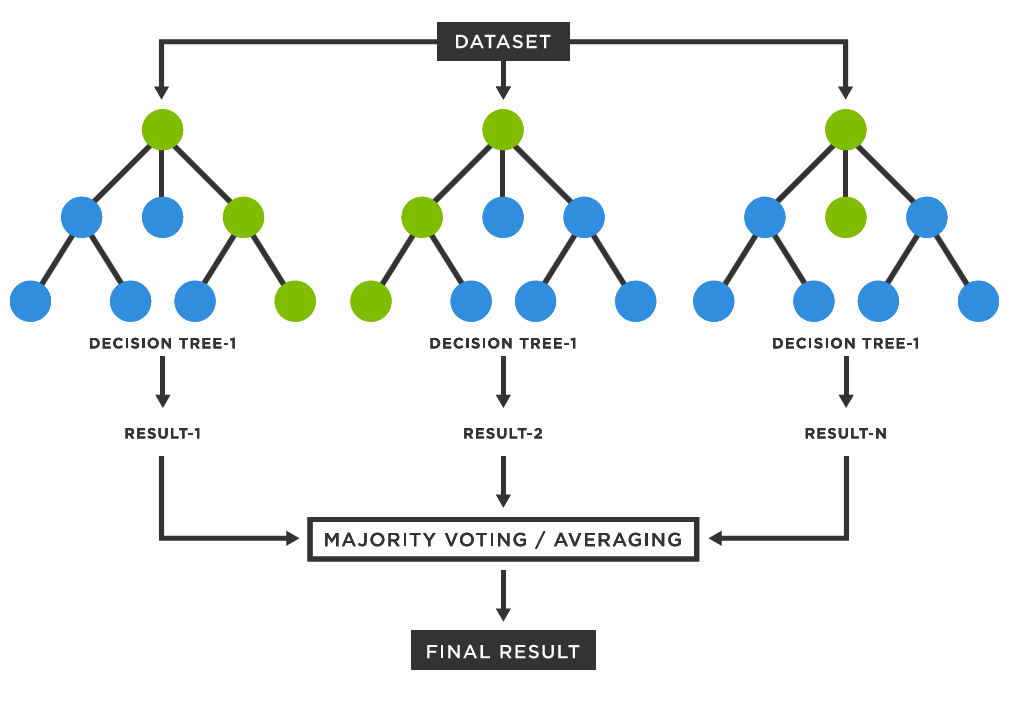
Os principais conceitos por trás do algoritmo incluem:
- Bagging (Bootstrap Aggregating): Cada árvore é treinada com um subconjunto aleatório dos dados, obtido via amostragem com reposição.
- Seleção Aleatória de Features: Cada árvore recebe apenas um subconjunto das features para tomar suas decisões, reduzindo correlações entre as árvores.
- Combinação de Previsões: No caso de classificação, a previsão final é feita por maioria de votos entre as árvores; no caso de regressão, é usada a média das previsões.
Essa abordagem ajuda a reduzir o overfitting e melhora a precisão do modelo.
Passos para Implementar Random Forest
- Criar uma Árvore de Decisão: O primeiro passo é implementar uma árvore de decisão básica. Cada árvore será treinada em um subconjunto aleatório dos dados.
- Amostragem Aleatória (Bootstrap): Para cada árvore na floresta, selecionamos um subconjunto aleatório dos dados de treinamento com reposição (bootstrap).
- Seleção Aleatória de Features: Em cada divisão da árvore, selecionamos um subconjunto aleatório de features para considerar a divisão. Isso ajuda a garantir que as árvores sejam diferentes umas das outras.
- Construir a Floresta: Repetimos o processo de construção de árvores várias vezes para criar a “floresta”.
- Combinação de Previsões: Para classificação, usamos a moda das previsões das árvores. Para regressão, usamos a média.
Implementação do Random Forest do Zero
Vamos iniciar definindo a classe para uma árvore de decisão:
import numpy as np
from collections import Counter
class DecisionTree:
def __init__(self, max_depth=None, min_samples_split=2, n_features=None):
self.max_depth = max_depth
self.min_samples_split = min_samples_split
self.n_features = n_features
self.root = None
A classe DecisionTree implementa uma árvore de decisão para tarefas de classificação. O construtor inicializa parâmetros como profundidade máxima, número mínimo de amostras para divisão e número de recursos a serem considerados.
def fit(self, X, y):
self.n_features = X.shape[1] if not self.n_features else min(self.n_features, X.shape[1])
self.root = self._grow_tree(X, y)
O método fit treina a árvore recursivamente, dividindo os dados com base no ganho de informação até atingir os critérios de parada.
def _grow_tree(self, X, y, depth=0):
n_samples, n_feats = X.shape
n_labels = len(np.unique(y))
if depth >= self.max_depth or n_labels == 1 or n_samples < self.min_samples_split:
leaf_value = self._most_common_label(y)
return Node(value=leaf_value)
feat_idxs = np.random.choice(n_feats, self.n_features, replace=False)
best_feat, best_thresh = self._best_split(X, y, feat_idxs)
left_idxs, right_idxs = self._split(X[:, best_feat], best_thresh)
left = self._grow_tree(X[left_idxs, :], y[left_idxs], depth+1)
right = self._grow_tree(X[right_idxs, :], y[right_idxs], depth+1)
return Node(best_feat, best_thresh, left, right)
A função _grow_tree é o coração da construção da árvore, decidindo quando criar nós folha ou continuar a divisão.
def _best_split(self, X, y, feat_idxs):
best_gain = -1
split_idx, split_thresh = None, None
for feat_idx in feat_idxs:
X_column = X[:, feat_idx]
thresholds = np.unique(X_column)
for thresh in thresholds:
gain = self._information_gain(y, X_column, thresh)
if gain > best_gain:
best_gain = gain
split_idx = feat_idx
split_thresh = thresh
return split_idx, split_thresh
def _information_gain(self, y, X_column, threshold):
parent_entropy = self._entropy(y)
left_idxs, right_idxs = self._split(X_column, threshold)
if len(left_idxs) == 0 or len(right_idxs) == 0:
return 0
n = len(y)
n_l, n_r = len(left_idxs), len(right_idxs)
e_l, e_r = self._entropy(y[left_idxs]), self._entropy(y[right_idxs])
child_entropy = (n_l/n) * e_l + (n_r/n) * e_r
information_gain = parent_entropy - child_entropy
return information_gain
def _split(self, X_column, split_thresh):
left_idxs = np.argwhere(X_column <= split_thresh).flatten()
right_idxs = np.argwhere(X_column > split_thresh).flatten()
Os métodos auxiliares, _best_split, _information_gain e _split, lidam com a seleção do melhor recurso e limiar para divisão, calculando o ganho de informação e dividindo os dados.
def _entropy(self, y):
hist = np.bincount(y)
ps = hist / len(y)
return -np.sum([p * np.log(p) for p in ps if p > 0])
def _most_common_label(self, y):
counter = Counter(y)
return counter.most_common(1)[0][0]
As funções _entropy e _most_common_label calculam a entropia e encontram o rótulo mais comum, respectivamente.
def predict(self, X):
return np.array([self._traverse_tree(x, self.root) for x in X])
def _traverse_tree(self, x, node):
if node.is_leaf():
return node.value
if x[node.feature] <= node.threshold:
return self._traverse_tree(x, node.left)
return self._traverse_tree(x, node.right)
Os métodos predict e _traverse_tree permitem fazer previsões percorrendo a árvore.
Agora, implementamos o Random Forest:
class Node:
def __init__(self, feature=None, threshold=None, left=None, right=None, value=None):
self.feature = feature
self.threshold = threshold
self.left = left
self.right = right
self.value = value
def is_leaf(self):
return self.value is not None
class RandomForest:
def __init__(self, n_trees=100, max_depth=10, min_samples_split=2, n_features=None):
self.n_trees = n_trees
self.max_depth = max_depth
self.min_samples_split = min_samples_split
self.n_features = n_features
self.trees = []
A classe RandomForest constrói um conjunto de árvores de decisão para criar um modelo mais robusto. O construtor inicializa o número de árvores e os parâmetros para cada árvore.
def fit(self, X, y):
self.trees = []
for _ in range(self.n_trees):
tree = DecisionTree(max_depth=self.max_depth,
min_samples_split=self.min_samples_split,
n_features=self.n_features)
X_sample, y_sample = self._bootstrap_samples(X, y)
tree.fit(X_sample, y_sample)
self.trees.append(tree)
O método fit treina a floresta criando várias árvores de decisão, cada uma treinada em um subconjunto de dados de treinamento gerado por amostragem bootstrap.
def _bootstrap_samples(self, X, y):
n_samples = X.shape[0]
idxs = np.random.choice(n_samples, n_samples, replace=True)
return X[idxs], y[idxs]
O método _bootstrap_samples cria subconjuntos de dados aleatórios.
def predict(self, X):
tree_preds = np.array([tree.predict(X) for tree in self.trees])
tree_preds = np.swapaxes(tree_preds, 0, 1)
return np.array([self._most_common_label(pred) for pred in tree_preds])
def _most_common_label(self, y):
counter = Counter(y)
return counter.most_common(1)[0][0]
O método predict faz previsões combinando as previsões de todas as árvores usando votação majoritária. A função _most_common_label auxilia na votação, encontrando o rótulo mais comum entre as previsões das árvores.
Testando a Implementação com um Dataset Real
Vamos testar nossa implementação utilizando o conjunto de dados Iris:
if __name__ == "__main__":
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
data = load_iris()
X, y = data.data, data.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
rf = RandomForest(n_trees=100, max_depth=10)
rf.fit(X_train, y_train)
preds = rf.predict(X_test)
print(f"Accuracy: {accuracy_score(y_test, preds)}")
Accuracy: 1.0Código completo
import numpy as np
from collections import Counter
class DecisionTree:
def __init__(self, max_depth=None, min_samples_split=2, n_features=None):
self.max_depth = max_depth
self.min_samples_split = min_samples_split
self.n_features = n_features
self.root = None
def fit(self, X, y):
self.n_features = X.shape[1] if not self.n_features else min(self.n_features, X.shape[1])
self.root = self._grow_tree(X, y)
def _grow_tree(self, X, y, depth=0):
n_samples, n_feats = X.shape
n_labels = len(np.unique(y))
if depth >= self.max_depth or n_labels == 1 or n_samples < self.min_samples_split:
leaf_value = self._most_common_label(y)
return Node(value=leaf_value)
feat_idxs = np.random.choice(n_feats, self.n_features, replace=False)
best_feat, best_thresh = self._best_split(X, y, feat_idxs)
left_idxs, right_idxs = self._split(X[:, best_feat], best_thresh)
left = self._grow_tree(X[left_idxs, :], y[left_idxs], depth+1)
right = self._grow_tree(X[right_idxs, :], y[right_idxs], depth+1)
return Node(best_feat, best_thresh, left, right)
def _best_split(self, X, y, feat_idxs):
best_gain = -1
split_idx, split_thresh = None, None
for feat_idx in feat_idxs:
X_column = X[:, feat_idx]
thresholds = np.unique(X_column)
for thresh in thresholds:
gain = self._information_gain(y, X_column, thresh)
if gain > best_gain:
best_gain = gain
split_idx = feat_idx
split_thresh = thresh
return split_idx, split_thresh
def _information_gain(self, y, X_column, threshold):
parent_entropy = self._entropy(y)
left_idxs, right_idxs = self._split(X_column, threshold)
if len(left_idxs) == 0 or len(right_idxs) == 0:
return 0
n = len(y)
n_l, n_r = len(left_idxs), len(right_idxs)
e_l, e_r = self._entropy(y[left_idxs]), self._entropy(y[right_idxs])
child_entropy = (n_l/n) * e_l + (n_r/n) * e_r
information_gain = parent_entropy - child_entropy
return information_gain
def _split(self, X_column, split_thresh):
left_idxs = np.argwhere(X_column <= split_thresh).flatten()
right_idxs = np.argwhere(X_column > split_thresh).flatten()
return left_idxs, right_idxs
def _entropy(self, y):
hist = np.bincount(y)
ps = hist / len(y)
return -np.sum([p * np.log(p) for p in ps if p > 0])
def _most_common_label(self, y):
counter = Counter(y)
return counter.most_common(1)[0][0]
def predict(self, X):
return np.array([self._traverse_tree(x, self.root) for x in X])
def _traverse_tree(self, x, node):
if node.is_leaf():
return node.value
if x[node.feature] <= node.threshold:
return self._traverse_tree(x, node.left)
return self._traverse_tree(x, node.right)
class Node:
def __init__(self, feature=None, threshold=None, left=None, right=None, value=None):
self.feature = feature
self.threshold = threshold
self.left = left
self.right = right
self.value = value
def is_leaf(self):
return self.value is not None
class RandomForest:
def __init__(self, n_trees=100, max_depth=10, min_samples_split=2, n_features=None):
self.n_trees = n_trees
self.max_depth = max_depth
self.min_samples_split = min_samples_split
self.n_features = n_features
self.trees = []
def fit(self, X, y):
self.trees = []
for _ in range(self.n_trees):
tree = DecisionTree(max_depth=self.max_depth,
min_samples_split=self.min_samples_split,
n_features=self.n_features)
X_sample, y_sample = self._bootstrap_samples(X, y)
tree.fit(X_sample, y_sample)
self.trees.append(tree)
def _bootstrap_samples(self, X, y):
n_samples = X.shape[0]
idxs = np.random.choice(n_samples, n_samples, replace=True)
return X[idxs], y[idxs]
def predict(self, X):
tree_preds = np.array([tree.predict(X) for tree in self.trees])
tree_preds = np.swapaxes(tree_preds, 0, 1)
return np.array([self._most_common_label(pred) for pred in tree_preds])
def _most_common_label(self, y):
counter = Counter(y)
return counter.most_common(1)[0][0]
# Exemplo de uso
if __name__ == "__main__":
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
data = load_iris()
X, y = data.data, data.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
rf = RandomForest(n_trees=100, max_depth=10)
rf.fit(X_train, y_train)
preds = rf.predict(X_test)
print(f"Accuracy: {accuracy_score(y_test, preds)}")
Conclusão
Neste post, implementamos um algoritmo de Random Forest do zero em Python. Embora existam bibliotecas como Scikit-Learn que oferecem implementações otimizadas e fáceis de usar, entender o funcionamento interno do algoritmo é fundamental para qualquer cientista de dados. Esperamos que este post tenha ajudado a esclarecer como o Random Forest funciona e como você pode implementá-lo por conta própria.
Se você tiver alguma dúvida ou sugestão, sinta-se à vontade para deixar um comentário abaixo. Até a próxima!
Recomendação de livros
- Mãos à obra aprendizado de máquina com Scikit-Learn, Keras & TensorFlow: conceitos, ferramentas e técnicas para a construção de sistemas inteligentes.
- Python para análise de dados
- Estatística Prática Para Cientistas de Dados: 50 Conceitos Essenciais
- An Introduction to Statistical Learning (Python e R)
Related posts:
 Machine Learning from scratch: Implementando o SVM (Máquinas de Vetores de Suporte) em Python
Machine Learning from scratch: Implementando o SVM (Máquinas de Vetores de Suporte) em Python
 Machine Learning from scratch: Implementando o KNN (K vizinhos mais próximos) em Python
Machine Learning from scratch: Implementando o KNN (K vizinhos mais próximos) em Python
 A Importância da Validação Cruzada em Machine Learning
A Importância da Validação Cruzada em Machine Learning
 Machine Learning from Scratch: Implementando K-Means Clustering em Python
Machine Learning from Scratch: Implementando K-Means Clustering em Python