
Nos últimos anos, os Large Language Models (LLMs) revolucionaram a maneira como interagimos com a inteligência artificial (IA). Esses modelos avançados, como o GPT-4 da OpenAI e Gemini do Google, têm a capacidade de compreender e gerar texto com uma precisão impressionante. Mas como esses modelos funcionam e por que são tão importantes? Neste post, vamos explorar a mecânica dos LLMs e entender sua relevância no mundo atual.

O Que São Large Language Models (LLMs)?
Large Language Models são modelos de aprendizado profundo que utilizam arquiteturas de redes neurais, especialmente transformers, para processar e gerar linguagem natural. Eles são treinados em grandes volumes de texto, aprendendo padrões e estruturas da linguagem para prever a próxima palavra ou sequência em um dado contexto.
Como funcionam os LLMs?
1. Arquitetura Transformers
Antes da arquitetura Transformer revolucionar o campo do processamento de linguagem natural (PLN) em 2017 com o artigo “Attention is All You Need“, modelos como LSTMs (Long Short-Term Memory) dominavam o cenário. Apesar de sua relevância, esses modelos apresentavam limitações no aprendizado de dependências de longo alcance em sequências de texto, dificultando a compreensão de contextos mais amplos.

A introdução da arquitetura Transformer superou essas limitações ao utilizar mecanismos de atenção. Essa abordagem inovadora permite que o modelo atribua pesos dinâmicos à relevância de cada palavra em uma frase, aprimorando significativamente a capacidade de capturar relações complexas entre elementos distantes na sequência. Essa habilidade aprimorada de contextualização resultou em um salto significativo no desempenho de LLMs em diversas tarefas de PLN, como tradução automática, geração de texto e sumarização.
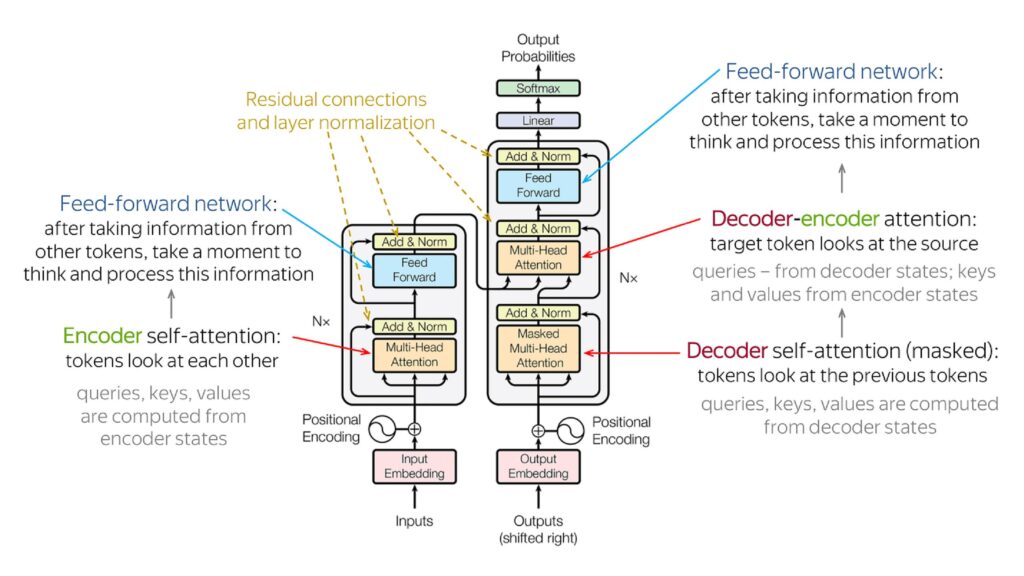
2. Treinamento em Massa
Coleta de Dados: Os LLMs são treinados em datasets massivos que incluem uma vasta gama de textos, desde livros e artigos científicos até conversas informais na internet. Esses dados são coletados e preparados para criar um corpus diversificado e representativo.
Pré-processamento dos Dados: O texto coletado é limpo e formatado, removendo inconsistências, duplicatas e caracteres especiais. Também é tokenizado, ou seja, dividido em unidades menores, como palavras ou sub-palavras, que podem ser processadas pelo modelo.
Treinamento Inicial: O modelo transformer é treinado em um supercomputador usando o corpus preparado. Esse treinamento inicial envolve o ajuste dos pesos das redes neurais através de backpropagation e otimização baseada em gradiente. O objetivo é minimizar a perda, que é uma medida de quão bem o modelo está prevendo a próxima palavra em uma sequência.
Fine-Tuning: Após o treinamento inicial, o modelo pode ser ajustado para tarefas específicas usando datasets menores e mais especializados. Isso permite que os modelos se adaptem a necessidades particulares, como atendimento ao cliente, tradução automática ou análise de sentimentos.
Tamanhos e Complexidade dos Modelos
Os LLMs variam amplamente em tamanho e complexidade, influenciando sua capacidade de compreensão e geração de texto:
- Modelos Pequenos: Como GPT-2 com 1.5 bilhões de parâmetros. São rápidos e eficientes, mas têm limitações em capturar dependências de longo alcance e nuances complexas da linguagem.
- Modelos Médios: Como GPT-3 com 175 bilhões de parâmetros. Oferecem um equilíbrio entre desempenho e recursos computacionais, capazes de entender e gerar texto com maior precisão.
- Modelos Gigantes: Como GPT-4 com trilhões de parâmetros. Oferecem desempenho de ponta em uma ampla gama de tarefas, mas exigem recursos computacionais substanciais para treinamento e inferência.

Conclusão
Large Language Models representam um avanço significativo na inteligência artificial, oferecendo capacidades poderosas para entender e gerar linguagem natural. Sua versatilidade e potencial para transformar diversas indústrias fazem deles uma ferramenta crucial no mundo moderno. No entanto, é essencial abordar os desafios éticos e técnicos associados a esses modelos para garantir seu uso responsável e sustentável.
Leitura Adicional:
Artigo Original do Transformers: Attention is all you need
Documentação do GPT-4: OpenAI GPT-4 Documentation
Livros Recomendados: Recomendações



Pingback: Engenharia de Prompt para LLMs: Dominando o zero-shot, few-shot e cadeia de pensamento - IA Com Café
Pingback: RAG em LLMs: Entendendo o Retrieval-Augmented Generation - IA Com Café
Pingback: Introdução aos agents de LLM - IA Com Café
Pingback: Interagindo com o pandas DataFrame através de agentes - IA Com Café
Pingback: Como se preparar para uma entrevista de ciência de dados: Guia completo com dicas e estratégias - IA Com Café