

MLOps, ou Machine Learning Operations, é uma abordagem para o desenvolvimento, implantação e manutenção de sistemas de machine learning de forma eficiente e escalável. É uma disciplina que combina princípios de engenharia de software, DevOps e ciência de dados para garantir que os modelos de machine learning sejam desenvolvidos com qualidade, implantados de forma confiável e mantenham um bom desempenho ao longo do tempo.
Por que MLOps é tão importante?

Enquanto os cientistas de dados se concentram na criação e treinamento de modelos de ML com desempenho preditivo em conjuntos de dados de validação off-line, a transição para a produção requer uma abordagem mais abrangente. A verdadeira dificuldade reside na integração e operação contínua desses modelos em ambientes de produção.
As empresas de tecnologia com experiência acumulada ao longo dos anos destacam as numerosas armadilhas encontradas ao operar sistemas baseados em ML na produção. No final das contas o projeto não acaba no Jupyter Notebook e sabemos que é em produção que a criança chora e a mãe não ouve.
O diagrama acima ilustra claramente que apenas uma fração mínima de um sistema de ML real consiste no código de ML em si. O ecossistema completo é vasto e complexo, exigindo uma atenção meticulosa em todas as fases do ciclo de vida do modelo. Da preparação e limpeza de dados à implantação, monitoramento contínuo e manutenção, cada etapa apresenta desafios únicos que requerem expertise em MLOps para serem superados.
Portanto, a especialização em MLOps não apenas complementa as habilidades de modelagem de machine learning, mas é essencial para garantir que os modelos desenvolvidos sejam implementados e operados de forma eficaz e confiável na produção. É a ponte crucial entre a teoria e a prática, transformando conceitos abstratos em soluções tangíveis e impactantes no mundo real.
Níveis de Maturidade em MLOps
De acordo com o google, o nível de automação desses passos define a maturidade do processo de ML, que reflete a velocidade de treinamento de novos modelos com base em novos dados ou treinamento de novas implementações. As seções a seguir descrevem três níveis de MLOps, começando pelo nível mais comum, que não envolve automação, até a automatização de pipelines de ML e CI/CD.
Nível 0: processo manual
Este é o nível que a maioria dos projetos de machine learning se encontram atualmente, onde muitas equipes têm cientistas de dados e pesquisadores de ML capazes de criar modelos de última geração, mas o processo de criação e implantação dos modelos é totalmente manual.
Neste fase você está desenvolvendo as suas análises e modelos através do Jupyter Notebook e não tem idea de como colocar esse modelo em produção ou automatizar algumas das taferas dentro do processo de CRISP-DM que provavelmente você já está seguindo, se não sabe o que é isso, então olha esse post anterior, CRISP-DM: Uma Metodologia Estruturada para projetos de Ciencia de Dados.
Nível 1: automação de pipeline de ML
Neste nível de maturidade do MLOps, o foco está na automação do pipeline de machine learning para permitir o treinamento contínuo do modelo. Neste estágio, é essencial alcançar a entrega contínua do serviço de predição do modelo, garantindo que o modelo esteja sempre atualizado e pronto para lidar com novos dados.
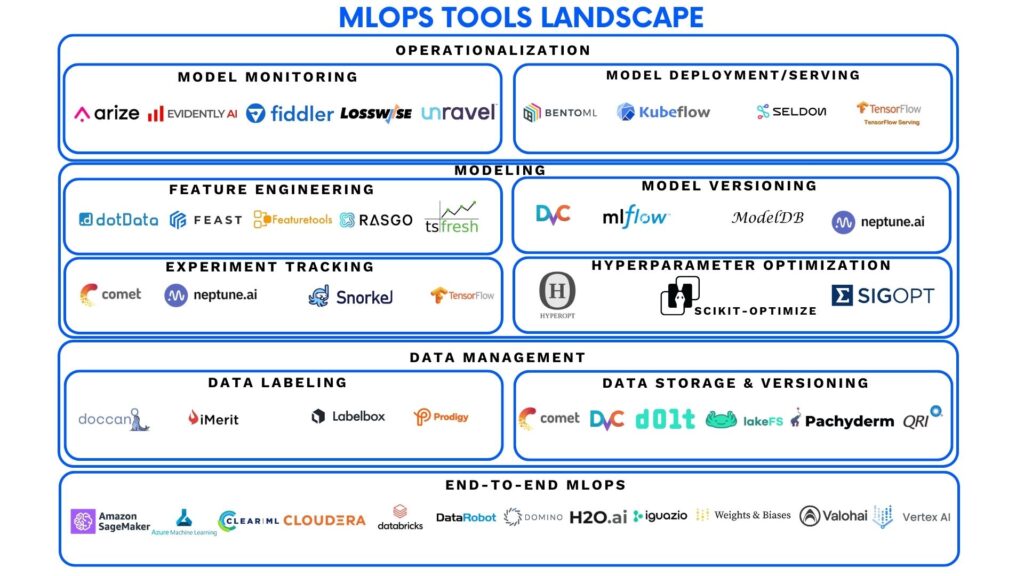
Nesta fase é possível utilizar uma variedade de ferramentas, como MLFlow para rastreamento e gerenciamento do ciclo de vida de modelos, Kedro para construção de pipelines de dados reprodutíveis, Docker para encapsular ambientes de execução de modelos em contêineres, Kubeflow para orquestração distribuída de pipelines de treinamento de modelos e TensorFlow para desenvolvimento, treinamento e integração de modelos em pipelines automatizados de implantação.
Quando lidando com poucas implementações de pipeline e estas não são atualizadas com frequência, é comum que o teste e a implantação dos componentes sejam feitos manualmente. Entretanto, para lidar com novas ideias de machine learning e implementações rápidas de novos componentes, especialmente ao gerenciar múltiplos pipelines de ML na produção, é crucial adotar uma abordagem de CI/CD para automatizar a criação, teste e implantação dos pipelines.
Isso garante uma resposta ágil e eficiente às demandas de implementação de novos modelos com base em novos dados, proporcionando um ambiente de desenvolvimento e produção mais dinâmico e adaptável.
Nível 2: automação de pipeline de CI/CD
Para garantir uma atualização ágil e confiável dos pipelines em produção, é fundamental contar com um sistema de CI/CD automatizado e robusto. Esse sistema permite que os cientistas de dados explorem rapidamente novas ideias em engenharia de atributos, arquitetura de modelos e hiperparâmetros. Assim, podem implementar e testar essas ideias de forma automatizada, garantindo uma entrega contínua dos novos componentes do pipeline no ambiente de destino.
Para ess nível de MLOps pode-se abranger os seguintes componentes:
- Controle de origem
- Serviços de teste e criação
- Serviços de implantação
- Registro de modelos
- Armazenamento de recursos
- Armazenamento de metadados de ML
- Orquestrador de pipeline de ML
O pipeline e os componentes dele são criados, testados e empacotados quando o novo código é confirmado ou enviado ao repositório de código-fonte. Além de criar pacotes, imagens de contêiner e executáveis, chamamos essa etapa de integração contínua (CI).
Quando o sistema entrega continuamente novas implementações de pipeline ao ambiente de destino que, por sua vez, fornece serviços de previsão do modelo recém-treinado, chamamos essa etapa de entrega contínua (CD).
Em resumo..
A implementação de machine learning em um ambiente de produção vai além da simples implantação de modelos como APIs de previsão. Envolve, na verdade, o estabelecimento de pipelines de ML capazes de automatizar tanto o treinamento quanto a implantação de novos modelos.
Ao configurar um sistema de CI/CD, é possível testar e implantar novas versões do pipeline de forma automática, permitindo adaptar-se rapidamente às mudanças nos dados e no ambiente de negócios. Não é necessário realizar uma transição abrupta de um estágio para outro; é viável implementar essas práticas gradualmente para aprimorar a automação do desenvolvimento e da produção do sistema de ML.
E por que eu deveria me especializar em MLOps?

- Demanda no mercado: Com a crescente adoção de machine learning em uma variedade de setores, há uma demanda crescente por profissionais que possam gerenciar o ciclo de vida completo dos modelos de machine learning, propondo melhorias e garantindo que as soluções de machine learning estejam sendo entregues ao cliente. Apesar de não ser uma profissão tão antiga, já temos um grande deficit de profissionais.
- Melhorar a eficiência: MLOps ajuda a automatizar tarefas repetitivas e a padronizar processos, o que pode aumentar significativamente a eficiência do desenvolvimento e implantação de modelos de machine learning. Você como um cientista de dados não deve esperar, comece implentando cada fase nos seus projetos e ganhe eficiência no seu próprio trabalho, crie as oportunidades.
- Garantir a qualidade: Implementar boas práticas de MLOps pode ajudar a garantir a qualidade dos modelos de machine learning, desde o desenvolvimento até a produção. Isso inclui testes automatizados, monitoramento de desempenho e controle de versão.
- Escalabilidade: MLOps permite escalar facilmente a implantação de modelos de machine learning para lidar com grandes volumes de dados e demandas de processamento.
- Redução de custos: Automatizar processos e otimizar recursos pode resultar em redução de custos operacionais.
Em resumo, especializar-se em MLOps pode abrir várias oportunidades de carreira emocionantes em um campo em crescimento e ajudá-lo a se destacar como um profissional de machine learning altamente qualificado e procurado.
Se quiser uma dica de leitura sobre essa assunto, acesse a página de livros recomendados.




Pingback: Boas Práticas de MLOps: Por Onde Começar? - IA Com Café