
Quando começamos a trabalhar com machine learning, é comum pensar que, quanto mais dados tivermos, melhor será o resultado do nosso modelo. No entanto, isso nem sempre é verdade. A escolha adequada das features (ou atributos) pode fazer uma diferença enorme na performance de um modelo. Mas o que são exatamente essas features?

O que são features?
As features são as variáveis que usamos para “ensinar” um modelo de machine learning. Cada feature contém uma característica ou atributo do nosso conjunto de dados. Por exemplo, no famoso dataset Titanic, algumas das features são:
- Idade do passageiro
- Classe da cabine
- Sexo
A escolha correta dessas features é importante para que o modelo consiga identificar padrões que ajudem a prever um resultado com precisão.
Seleção de features e engenharia de features
Existem dois conceitos importantes que todo ciêntista de dados deve entender:
- Seleção de Features: Aqui, escolhemos as variáveis que realmente agregam valor ao modelo, removendo aquelas que não são úteis ou que podem prejudicar a performance.
- Engenharia de Features: Envolve transformar as variáveis de forma que fiquem mais fáceis de interpretar pelo modelo. Isso pode incluir criar novas features a partir de outras ou modificar o formato de variáveis existentes.
Por que isso é importante?
A escolha e transformação das features podem impactar diretamente a precisão, velocidade e simplicidade do modelo. Se incluirmos muitas features irrelevantes, o modelo pode ter dificuldade em aprender, ficar lento e ter um desempenho ruim em novos dados (overfitting). Já com um bom conjunto de features, ele consegue focar no que realmente importa, resultando em um modelo mais eficiente.
Escolher as variáveis corretas pode não apenas aumentar a performance do modelo, mas também garantir que ele generalize bem para dados não vistos. Aqui estão algumas razões pelas quais a seleção de features é tão importante:
- Redução de Overfitting: Incluir muitas features irrelevantes pode fazer com que o modelo memorize os dados de treino em vez de aprender padrões. Isso resulta em uma performance fraca em dados novos.
- Melhoria da Interpretabilidade: Modelos com menos features são geralmente mais fáceis de interpretar, facilitando a comunicação dos resultados e decisões com stakeholders.
- Eficiência Computacional: Menos features significam menos cálculos, o que pode acelerar o treinamento e a predição, especialmente em grandes conjuntos de dados.
- Aumento da Acurácia: Features relevantes ajudam o modelo a capturar melhor os padrões dos dados, levando a um aumento na precisão.
Exemplos práticos de seleção e engenharia de features
Usaremos o dataset Titanic para mostrar como a seleção de atributos impacta o desempenho. O objetivo é prever se um passageiro sobreviveu ou não ao desastre do Titanic.
Passo 1: Importando o Dataset
Primeiro, vamos carregar o dataset e visualizar suas features iniciais.
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
# Carregar dataset Titanic
url = 'https://raw.githubusercontent.com/datasciencedojo/datasets/master/titanic.csv'
data = pd.read_csv(url)
# Exibir primeiras linhas
data.head()

Passo 2: Analisando as Features
As principais features que temos são:
- Pclass: Classe do passageiro (1ª, 2ª ou 3ª classe)
- Sex: Sexo do passageiro
- Age: Idade do passageiro
- Fare: Valor da passagem
- Embarked: Porto de embarque
- Survived: Se o passageiro sobreviveu (essa é a variável que queremos prever, ou seja, nosso “label”)
Passo 3: Seleção de features simples
Vamos começar selecionando algumas das features que parecem mais relevantes. Sabemos que a classe do passageiro, idade e sexo são fatores importantes.
# Selecionar features mais relevantes
features = ['Pclass', 'Sex', 'Age', 'Fare']
X = data[features]
y = data['Survived']
# Preencher valores ausentes na coluna 'Age' com a mediana
X['Age'].fillna(X['Age'].median(), inplace=True)
# Transformar a coluna 'Sex' em valores numéricos (0 = female, 1 = male)
X['Sex'] = X['Sex'].map({'male': 1, 'female': 0})
# Dividir os dados em treino e teste
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Treinar o modelo
model = RandomForestClassifier()
model.fit(X_train, y_train)
# Fazer previsões e calcular acurácia
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f'Acurácia com features simples: {accuracy:.2f}')
Acurácia com features simples: 0.78Passo 4: Engenharia de Features
Agora vamos melhorar a performance do modelo com a engenharia de features. Algumas ideias:
- Criar a feature “Tamanho da Família” somando o número de irmãos/esposas e pais/filhos a bordo.
- Transformar o valor da passagem (Fare) em categorias, para capturar melhor as diferenças entre passageiros ricos e pobres.
# Criar feature 'Tamanho da Família'
data['FamilySize'] = data['SibSp'] + data['Parch']
# Categorizar a coluna 'Fare'
data['Fare_cat'] = pd.qcut(data['Fare'], 4, labels=[1, 2, 3, 4])
# Atualizar features com novas variáveis
features_engineered = ['Pclass', 'Sex', 'Age', 'FamilySize', 'Fare_cat']
X_engineered = data[features_engineered]
# Preencher valores ausentes e mapear 'Sex' como antes
X_engineered['Age'].fillna(X_engineered['Age'].median(), inplace=True)
X_engineered['Sex'] = X_engineered['Sex'].map({'male': 1, 'female': 0})
# Dividir os dados novamente
X_train_eng, X_test_eng, y_train_eng, y_test_eng = train_test_split(X_engineered, y, test_size=0.2, random_state=42)
# Treinar e avaliar o novo modelo
model.fit(X_train_eng, y_train_eng)
y_pred_eng = model.predict(X_test_eng)
accuracy_eng = accuracy_score(y_test_eng, y_pred_eng)
print(f'Acurácia com features aprimoradas: {accuracy_eng:.2f}')
Acurácia com features aprimoradas: 0.81Impacto nas Métricas
Ao adicionar essas novas features, conseguimos melhorar a acurácia do nosso modelo. Isso mostra como a seleção e a criação de features impactam diretamente as métricas de avaliação.
Implementando técnicas mais avançadas de seleção de features
No Titanic, além das features que já discutimos, podemos usar técnicas de seleção de features como:
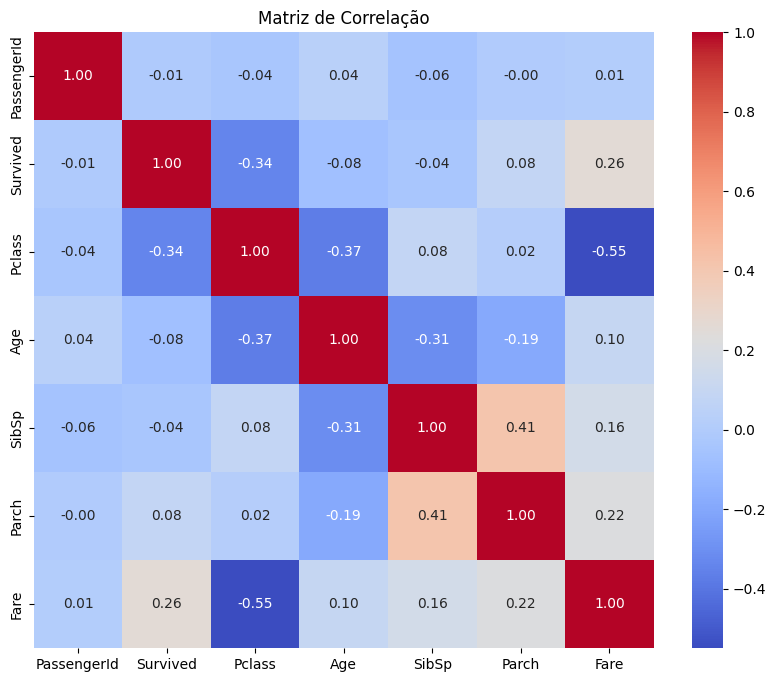
1. Análise de Correlação: Podemos usar a correlação para identificar quais features têm maior relação com a variável alvo (sobrevivência).
A correlação indica uma relação entre duas variáveis, mas não necessariamente uma relação de causa e efeito, então precisamos ter isso em mente ao avaliar a seleção das features.
import seaborn as sns
import matplotlib.pyplot as plt
# Calcular a matriz de correlação, utilizando apenas as colunas numéricas.
correlation_matrix = data.select_dtypes(include=['number']).corr()
# Plotar a matriz de correlação
plt.figure(figsize=(10, 8))
sns.heatmap(correlation_matrix, annot=True, cmap='coolwarm', fmt='.2f')
plt.title('Matriz de Correlação')
plt.show()
2. Recursive Feature Elimination (RFE): Esta técnica utiliza um modelo para selecionar features, eliminando as menos significativas.
from sklearn.feature_selection import RFE
from sklearn.linear_model import LogisticRegression
# Modelo de regressão logística
model = LogisticRegression(max_iter=1000)
rfe = RFE(model, n_features_to_select=3)
fit = rfe.fit(X_train, y_train)
# Features selecionadas
print("Features selecionadas:", X_train.columns[fit.support_])
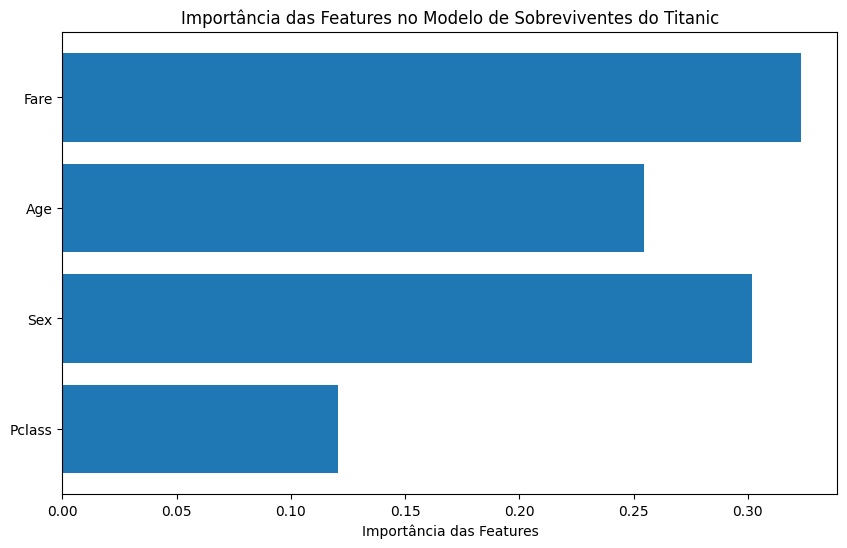
Features selecionadas: Index(['Pclass', 'Sex', 'Age'], dtype='object')3. Validação de Importância de Features: Após treinar um modelo, podemos verificar a importância das features para entender seu impacto.
from sklearn.ensemble import RandomForestRegressor
# Treinar um modelo Random Forest
model = RandomForestRegressor()
model.fit(X_train, y_train)
# Importância das features
importances = model.feature_importances_
# Plotar a importância das features
plt.figure(figsize=(10, 6))
plt.barh(X_train.columns, importances)
plt.xlabel('Importância das Features')
plt.title('Importância das Features no Modelo de Sobreviventes do Titanic')
plt.show()
Problemas relacionados às features
Existem vários problemas relacionados às features que podem impactar o desempenho e a generalização dos modelos de machine learning:
Dados Ausentes (Missing Values):
- A presença de dados ausentes pode comprometer a análise e o desempenho do modelo. Existem várias abordagens para lidar com isso, como a imputação (substituição de valores ausentes por médias, medianas, ou valores mais comuns) ou a exclusão de registros incompletos.
Outliers:
- Valores extremos podem distorcer a análise estatística e o desempenho do modelo. Técnicas de detecção de outliers (como boxplots e z-scores) podem ser usadas para identificar e decidir se devem ser removidos ou tratados.
Escalonamento de Features (Feature Scaling):
- Modelos sensíveis à escala das variáveis (como KNN e SVM) podem ter seu desempenho prejudicado se as features não forem escaladas adequadamente. Técnicas como normalização (min-max scaling) e padronização (z-score) são comuns.
Variáveis Categóricas Não Tratadas:
- Features categóricas precisam ser convertidas em um formato numérico para que possam ser utilizadas em modelos. Técnicas como one-hot encoding e label encoding são fundamentais.
High Cardinality:
- Quando uma feature categórica possui muitos níveis únicos (alta cardinalidade), isso pode levar a problemas de sobreajuste (overfitting). Técnicas de agrupamento ou o uso de embeddings podem ajudar a contornar esse problema.
Relevância das Features:
- Features irrelevantes ou redundantes podem reduzir a acurácia do modelo e aumentar o tempo de treinamento. Técnicas de seleção de features ajudam a identificar quais features são mais importantes.
Interação entre Features:
- Algumas features podem interagir entre si, afetando a saída do modelo de maneira não linear. Criar features que representem essas interações (por exemplo, multiplicação ou combinação) pode melhorar a performance.
Distribuição Não Normal:
- Algumas técnicas estatísticas e de machine learning assumem que os dados seguem uma distribuição normal. Se as features não forem normalmente distribuídas, pode ser necessário aplicar transformações (como log ou raiz quadrada).
Variação na Amostra:
- Se as features contêm muita variação (high variance) em diferentes subconjuntos dos dados, isso pode levar a um desempenho inconsistente do modelo. Técnicas de regularização (como L1 e L2) podem ajudar a controlar isso.
Multicolinearidade:
- A multicolinearidade ocorre quando duas ou mais features são altamente correlacionadas, o que pode dificultar a interpretação dos coeficientes e a estabilidade do modelo.
Os problemas relacionados às features têm impacto direto no sucesso dos modelos de machine learning. Desde dados ausentes até multicolinearidade, cada questão exige atenção para garantir que o modelo aprenda de forma eficiente e generalize bem em dados não vistos. O tratamento adequado desses problemas pode melhorar a acurácia, reduzir o risco de overfitting e acelerar o tempo de processamento
Conclusão
Neste artigo, exploramos a seleção de features e como essa escolha impacta diretamente o desempenho dos modelos de machine learning. Ao abordar conceitos como a relevância das features, a importância do escalonamento, a detecção de outliers, e a eliminação de variáveis redundantes, demonstramos que o pré-processamento cuidadoso é essencial para garantir que os modelos sejam eficientes, precisos e generalizem bem. Além disso, com exemplos práticos em Python utilizando datasets como Titanic, mostramos como técnicas de seleção e engenharia de features podem melhorar significativamente as métricas de performance dos modelos. Com a correta compreensão e aplicação desses conceitos, é possível elevar o nível das previsões e dos insights gerados, maximizando o valor que os modelos podem trazer ao mundo real.
A seleção de features não é apenas uma etapa técnica, mas uma habilidade crítica para cientistas de dados, que podem transformar um conjunto de dados complexo em algo mais interpretável e útil, impactando diretamente nos resultados dos projetos.
Recomendação de livros



Pingback: Regularização em Machine Learning: Técnicas e Benefícios para Modelos Mais Robustos - IA Com Café