
Se você trabalha com análise de dados em Python, já deve conhecer o Pandas, uma das bibliotecas mais poderosas e versáteis para manipulação de dados. No entanto, além das funções básicas, o Pandas oferece técnicas avançadas que podem elevar sua produtividade e eficiência. Neste post, vamos explorar 10 técnicas avançadas de manipulação com Pandas que todo analista de dados ou cientista de dados deve dominar.

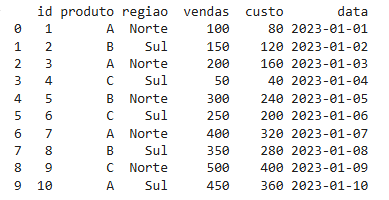
Antes de qualquer coisa, vamos criar um dataset fictício para demonstrar cada uma das 10 técnicas e manipulação com Pandas deste post. O dataset representa vendas de uma loja de varejo, com informações sobre produtos, vendas, regiões e datas.
Dataset: Vendas de uma loja de varejo
import pandas as pd
# Criando o DataFrame
data = {
'id': [1, 2, 3, 4, 5, 6, 7, 8, 9, 10],
'produto': ['A', 'B', 'A', 'C', 'B', 'C', 'A', 'B', 'C', 'A'],
'regiao': ['Norte', 'Sul', 'Norte', 'Sul', 'Norte', 'Sul', 'Norte', 'Sul', 'Norte', 'Sul'],
'vendas': [100, 150, 200, 50, 300, 250, 400, 350, 500, 450],
'custo': [80, 120, 160, 40, 240, 200, 320, 280, 400, 360],
'data': pd.to_datetime(['2023-01-01', '2023-01-02', '2023-01-03', '2023-01-04', '2023-01-05',
'2023-01-06', '2023-01-07', '2023-01-08', '2023-01-09', '2023-01-10'])
}
df = pd.DataFrame(data)
print(df)
1 – Selecionando os maiores e menores valores com nlargest() e nsmallest()
Essas funções permitem que você encontre rapidamente as N maiores ou menores entradas em um DataFrame. Em vez de ordenar manualmente, você pode usar nlargest() e nsmallest() para obter os resultados desejados de forma eficiente.
# Top 3 maiores vendas
top_vendas = df.nlargest(3, 'vendas')
print(top_vendas)
# Top 2 menores custos
menores_custos = df.nsmallest(2, 'custo')
print(menores_custos)

2 – Aplicando transformações com transform()
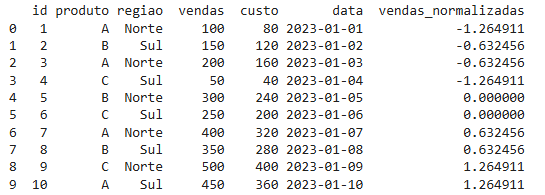
A função transform() é ideal para aplicar uma função a cada elemento de uma coluna ou grupo, mantendo o formato original do DataFrame. É especialmente útil para normalização de dados ou criação de novas colunas com base em cálculos.
# Normalizar vendas por região
df['vendas_normalizadas'] = df.groupby('regiao')['vendas'].transform(lambda x: (x - x.mean()) / x.std())
print(df)
3 – Criando novas colunas com assign()
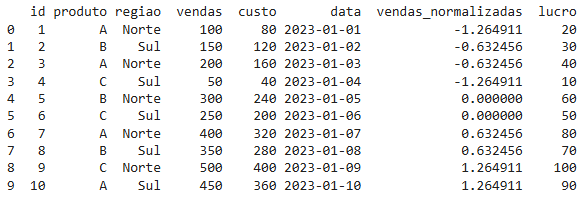
Com assign(), você pode adicionar novas colunas ao DataFrame de forma dinâmica e encadeada, sem modificar o DataFrame original. Isso é ótimo para pipelines de processamento de dados.
# Adicionar uma coluna de lucro
df = df.assign(lucro = df['vendas'] - df['custo'])
print(df)
4 – Transformando dados em formato longo com melt()
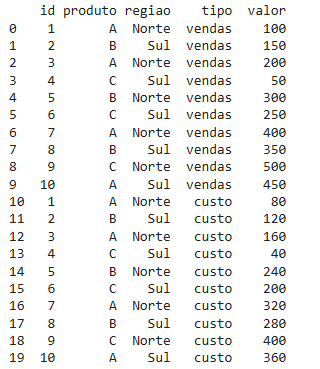
A função melt() é usada para transformar colunas em linhas, facilitando a reorganização de dados para análises mais detalhadas. É uma técnica essencial para trabalhar com dados em formato “wide” (largo).
# Transformar colunas 'vendas' e 'custo' em linhas
df_melted = df.melt(id_vars=['id', 'produto', 'regiao'], value_vars=['vendas', 'custo'], var_name='tipo', value_name='valor')
print(df_melted)
5 – Copiando dados diretamente da área de transferência com read_clipboard()
Essa função permite importar dados diretamente da área de transferência para um DataFrame. É extremamente útil para análises rápidas ou quando você precisa copiar dados de uma tabela na web ou de um documento.
1 – Copie a tabela abaixo para a área de transferência:
id,produto,regiao,vendas,custo,data
11,D,Norte,600,480,2023-01-11
12,D,Sul,550,440,2023-01-122 – Use o código:
df_novos_dados = pd.read_clipboard()
print(df_novos_dados)
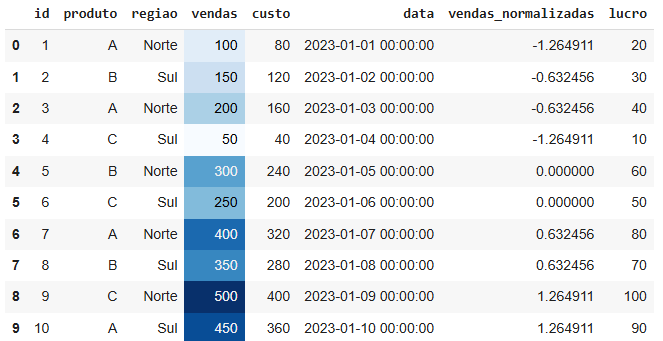
6 – Melhorando a visualização com df.style
O df.style permite formatar e estilizar visualizações de DataFrames diretamente no Jupyter Notebook. Você pode aplicar cores, gradientes e outras formatações para destacar insights importantes.
# Aplicar gradiente de cores na coluna de vendas
df.style.background_gradient(subset=['vendas'], cmap='Blues')
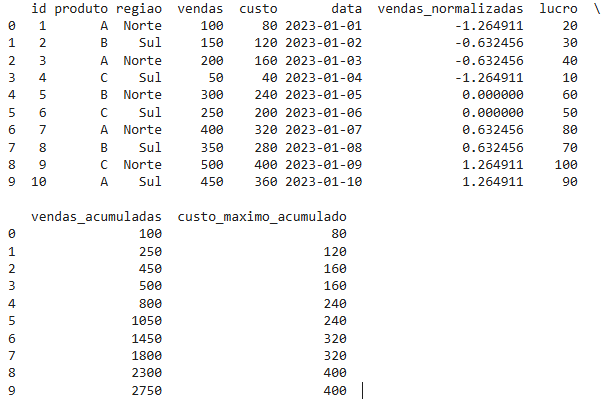
7 – Cálculos Acumulativos com cumsum(), cumprod(), cummax() e cummin()
Essas funções de acumulação permitem calcular valores cumulativos, como soma acumulada, produto acumulado, máximo acumulado e mínimo acumulado. São ideais para análises temporais ou sequenciais.
# Soma acumulada de vendas
df['vendas_acumuladas'] = df['vendas'].cumsum()
# Máximo acumulado de custos
df['custo_maximo_acumulado'] = df['custo'].cummax()
print(df)
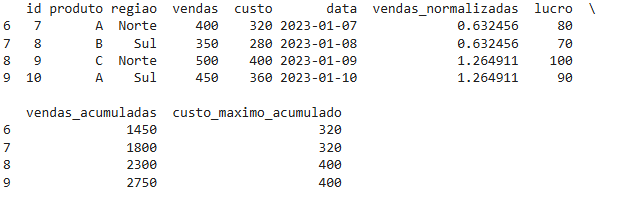
8 – Agregação personalizada com groupby().agg()
A combinação de groupby() e agg() é poderosa para agregação de dados. Você pode aplicar múltiplas funções de agregação (como soma, média, mediana) em diferentes colunas de uma só vez.
# Agregar vendas e custos por região
df_agg = df.groupby('regiao').agg({'vendas': 'sum', 'custo': 'mean'})
print(df_agg)

9 – Filtrando dados com query()
A função query() permite filtrar DataFrames usando expressões simples, sem a necessidade de escrever código complexo. É uma maneira eficiente de selecionar subconjuntos de dados.
# Exemplo: Filtrar dados
df_filtrado = df.query('coluna1 > 50 and coluna2 == "valor"')
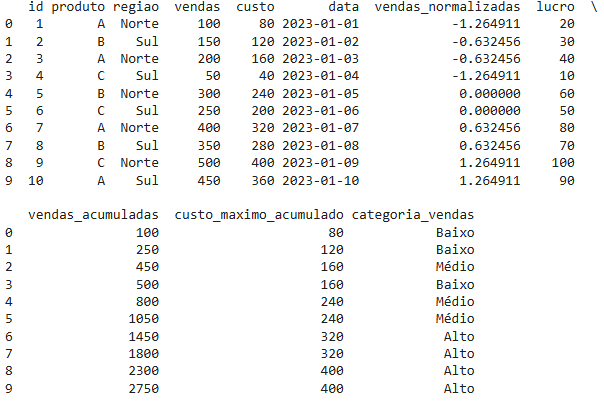
10 – Criando faixas de valores com pd.qcut()
A função pd.qcut() é usada para dividir dados em quantis, criando intervalos de valores com base em percentis. É útil para categorizar dados contínuos em grupos.
# Dividir vendas em 3 categorias (Baixo, Médio, Alto)
df['categoria_vendas'] = pd.qcut(df['vendas'], q=3, labels=['Baixo', 'Médio', 'Alto'])
print(df)
Conclusão
Dominar essas 10 técnicas avançadas de manipulação com Pandas pode transformar a maneira como você trabalha com dados, tornando suas análises mais rápidas, eficientes e poderosas. Experimente e veja como elas podem otimizar sua análise de dados!
Se você gostou deste conteúdo, compartilhe e siga para mais dicas avançadas de Python e Data Science!
Recomendação de livros
- Mãos à obra aprendizado de máquina com Scikit-Learn, Keras & TensorFlow: conceitos, ferramentas e técnicas para a construção de sistemas inteligentes.
- Python para análise de dados
- Estatística Prática Para Cientistas de Dados: 50 Conceitos Essenciais
- An Introduction to Statistical Learning (Python e R)
Related posts:
 5 dicas para melhorar a preparação dos seus dados em projetos de machine learning
5 dicas para melhorar a preparação dos seus dados em projetos de machine learning
 Aprendizado baseado em instâncias e baseado em modelos: Entenda as diferenças
Aprendizado baseado em instâncias e baseado em modelos: Entenda as diferenças
 Top livros que todo Cientista de Dados deveria ter
Top livros que todo Cientista de Dados deveria ter
 Como se preparar para uma entrevista de ciência de dados: Guia completo com dicas e estratégias
Como se preparar para uma entrevista de ciência de dados: Guia completo com dicas e estratégias