O Machine Learning Operations (MLOps) é um conjunto de práticas que visa a unificação do desenvolvimento (Dev) e das operações (Ops) aplicadas ao machine learning. Para cientistas de dados que desejam evoluir seus notebooks para código Python mais estruturado e robusto, adotar boas práticas de MLOps é fundamental. Neste post, vamos explorar as primeiras iniciativas que você deve considerar e destacar ferramentas essenciais como Kedro e MLFlow.

O propósito dos notebooks
Embora os Notebooks Jupyter sejam ferramentas essenciais para cientistas de dados, eles não são suficientes para entregar modelos de machine learning em um ambiente de produção. Ao implementar práticas de MLOps, os cientistas de dados podem superar as limitações dos Notebooks Jupyter e garantir que seus modelos sejam entregues de forma eficiente e confiável.
Então podemos começar implementando duas ferramentas que serão essenciais nesta jornada: Kedro e MLFlow.
1. Estruture Seu Projeto com Kedro
Kedro é uma ferramenta de código aberto desenvolvida pela QuantumBlack que ajuda a estruturar projetos de data science e machine learning. Ele segue princípios de engenharia de software, como modularidade e reprodutibilidade, facilitando a manutenção e escalabilidade dos projetos.
Ele oferece recursos incorporados automaticamente, incluindo parametrização, abstração de pipeline e visualização de pipeline. Além disso, o Kedro pode expandir rapidamente os pipelines criados com a estrutura e gerenciar conjuntos de dados massivos.
Por que usar Kedro?
- Estrutura Modular: Kedro organiza o código em módulos claros e separados, como
data,modelsepipelines. - Reprodutibilidade: Facilita a criação de pipelines de dados que podem ser reproduzidos de maneira consistente.
- Colaboração: Melhora a colaboração entre equipes ao fornecer uma estrutura padrão para projetos.
Primeiros passos com Kedro
Siga a documentação oficial para criar um projeto padrão: spaceflights project
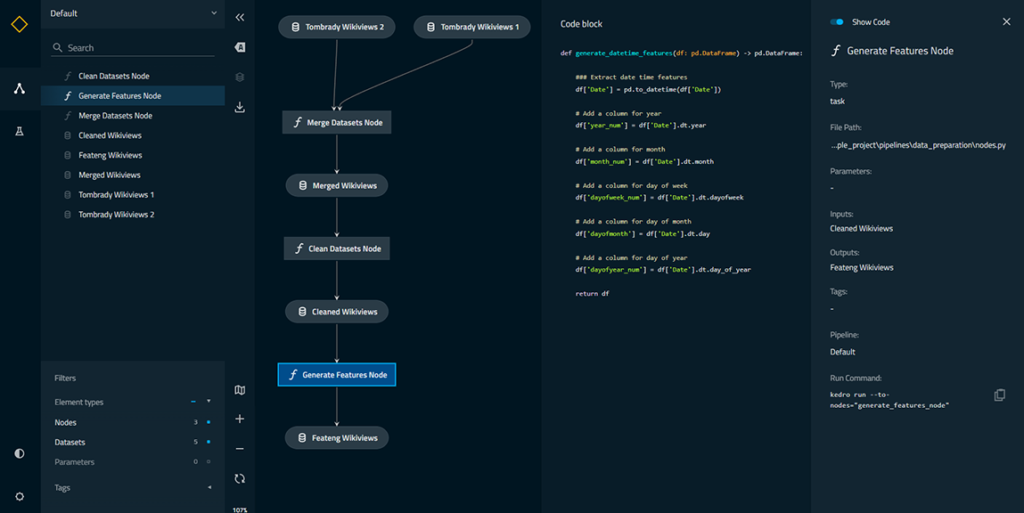
Ao final você será capaz de gerar uma visualização com todas as pipelines com funções, processos dos dados e códigos, como abaixo:
2. Gerencie seus Experimentos com MLFlow
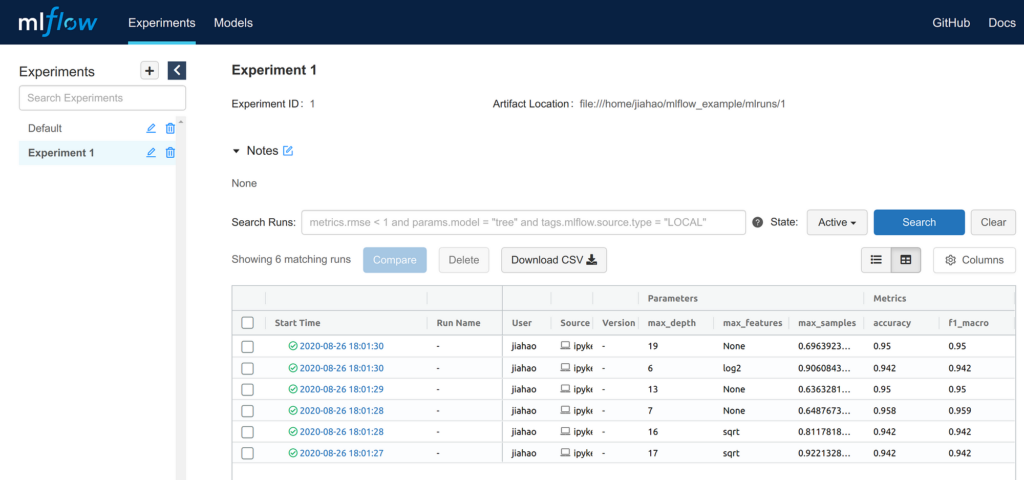
MLFlow é uma plataforma de código aberto para gerenciar o ciclo de vida de modelos de machine learning. Ela permite rastrear experimentos, registrar e versionar modelos, e gerenciar pipelines de ML, tudo isso a partir de uma interface bastante amigável que torna simples o trabalho de comparação e gerenciamento de modelos de ML.
Benefícios do MLFlow
- Rastreamento de Experimentos: Mantém um histórico de todos os experimentos, parâmetros e resultados.
- Registro de Modelos: Facilita o armazenamento e versionamento de modelos.
- Integração com CI/CD: Pode ser integrado a pipelines de CI/CD para automação do ciclo de vida do modelo.
Na documentação oficial existem vários tutoriais sobre como dar os primeiros passos com MLFlow.
Conclusão
Implementar MLOps desde o início pode parecer desafiador, mas os benefícios em termos de reprodutibilidade, escalabilidade e eficiência valem o esforço. Comece aos poucos, incorporando essas ferramentas e práticas ao seu fluxo de trabalho, e veja a diferença que elas podem fazer na sua produtividade e na qualidade dos seus projetos de machine learning.
A combinação de Kedro e MLflow oferece uma solução abrangente para levar modelos de machine learning da pesquisa à produção. A estrutura modular do Kedro, aliada às capacidades de tracking e deployment do MLflow, cria um ambiente ideal para construir pipelines de dados escaláveis e confiáveis. Essa abordagem permite que as empresas tirem o máximo proveito de seus dados, entregando soluções de machine learning que geram valor real para o negócio

Leitura Adicional
Combinação poderosa de Kedro + MLFlow
Blog do MLFlow
Blog do Kedro
Livros recomendados: Recomendações