
Em Machine Learning, a criação de modelos preditivos precisos e robustos é um dos principais objetivos a serem alcançados. Uma das técnicas mais eficazes para isso é o uso de modelos ensemble. Mas o que são modelos ensemble e como funcionam as técnicas de Bagging, Boosting e Stacking?
O que são Modelos Ensemble?
Modelos ensemble são métodos que combinam as previsões de vários modelos base para melhorar a precisão e a robustez das previsões mais refinadas. A ideia principal por trás dos modelos ensemble é que a combinação de múltiplos modelos pode capturar diferentes padrões e reduzir o risco de overfitting, resultando em um desempenho geral melhor do que qualquer modelo individual.
Existem várias técnicas para construir modelos ensemble, entre as mais populares estão o Bagging, Boosting e Stacking. Vamos ver como cada uma dessas técnicas funciona.
Bagging (Bootstrap Aggregating)
Bagging, ou Bootstrap Aggregating, é uma técnica de ensemble que busca reduzir a variância do modelo base. A ideia é simples: vários modelos são treinados de forma independente, cada um em uma amostra diferente do conjunto de dados de treinamento, criada por amostragem com reposição (bootstrap). As previsões dos modelos são então combinadas por média (para regressão) ou por votação majoritária (para classificação).
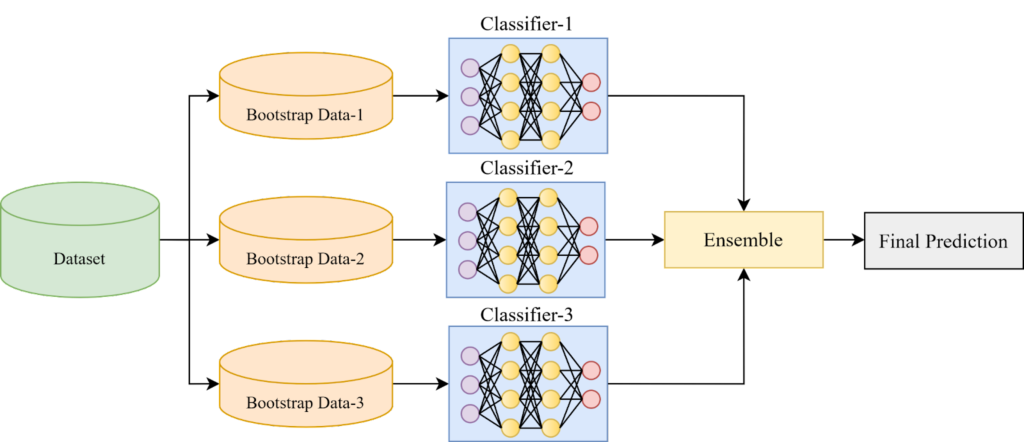
Essa estratégia contribui para a criação de modelos robustos e menos propensos ao overfitting, como os modelos baseados em Bagging geralmente apresentam alta variância e baixo viés. Essa combinação os torna modelos complexos com um elevado número de parâmetros treináveis. No entanto, o Bagging atua de forma a atenuar essa alta variância, resultando em um modelo final mais preciso e confiável.
Exemplo popular: Random Forest
Passo a passo:
1 – Definição do Modelo Base: Escolha um modelo de aprendizado de máquina base, como uma árvore de decisão.
2 – Criação de Subconjuntos: Crie múltiplos subconjuntos do conjunto de dados original utilizando a técnica de bootstrap.
3 – Treinamento dos Modelos Individuais: Treine o modelo base em cada um dos subconjuntos de dados.
4 – Agregação das Previsões: Para cada ponto de dados de teste, obtenha a predição de cada modelo base. A previsão final para o ponto de dados é geralmente obtida pela média das previsões individuais (para regressão) ou pela maioria das classes preditas (para classificação).
Boosting
Boosting é uma técnica de ensemble que combina modelos fracos sequencialmente, com cada modelo corrigindo os erros de seu predecessor. A ideia é treinar modelos de forma iterativa, ajustando as instâncias de dados que foram mal previstas pelos modelos anteriores, atribuindo-lhes maiores pesos.
Ao invés de utilizar um único modelo complexo, o Boosting combina diversos modelos simples para construir um modelo final mais robusto e preciso.

O principal objetivo do método boosting é reduzir o viés na decisão do conjunto. Assim, os classificadores escolhidos para o conjunto geralmente precisam ter baixa variância e alto viés, ou seja, modelos mais simples e com parâmetros menos treináveis.
Exemplo popular: AdaBoost, Gradient Boosting, XGBoost
Passo a passo:
1 – Inicialização: Um modelo inicial simples, com alto viés e baixa variância, é treinado no conjunto de dados completo.
2 – Treinamento Sequencial:
2.1 Identificação de Erros
2.2 Treinamento de Novos Modelos
2.3 Atribuição de Pesos
2.4 Combinação de Modelos
3 – Repetição: As etapas 2a e 2b são repetidas diversas vezes, cada vez treinando um novo modelo fraco para corrigir os erros do conjunto atual.
4 – Modelo Final: O modelo final é formado pela combinação de todos os modelos fracos treinados, com pesos ajustados durante o processo.Stacking (Stacked Generalization)
Stacking (Stacked Generalization)
Stacking, também conhecido como “aprendizado por empilhamento”, é uma técnica de ensemble que combina diferentes tipos de modelos base e treina um modelo de nível meta (meta-learner) para combinar as previsões dos modelos base. O objetivo é explorar as forças de diferentes tipos de modelos para obter uma previsão final mais robusta.

Passo a passo:
1 – Treinamento de Modelos Base: Um conjunto de diversos modelos base, como árvores de decisão, redes neurais ou k-nearest neighbors (kNN), é treinado no conjunto de dados original.
2 – Criação de um Conjunto de Metadados: As previsões dos modelos base, juntamente com as variáveis originais do conjunto de dados, formam um novo conjunto de dados chamado de “conjunto de metadados”.
3 – Treinamento do Metamodelo: Um novo modelo, chamado de “metamodelo”, é treinado no conjunto de metadados. O objetivo do metamodelo é aprender como combinar as previsões dos modelos base de forma eficaz para gerar uma predição final otimizada.
4 – Previsão Final: Para prever novos dados, as previsões dos modelos base são obtidas e, em seguida, combinadas pelo metamodelo, gerando a previsão final mais precisa e informada.
Conclusão
Modelos ensemble são ferramentas poderosas em Machine Learning, capazes de melhorar significativamente a precisão e a robustez das previsões. Técnicas como Bagging, Boosting e Stacking oferecem diferentes abordagens para combinar múltiplos modelos e lidar com os desafios dos dados complexos.
Leitura Adicional:
https://www.v7labs.com/blog/ensemble-learning
https://medium.com/turing-talks/turing-talks-24-modelos-de-predi%C3%A7%C3%A3o-ensemble-learning-aa02ce01afda
Recomendação de livros
Estatística Prática para Cientistas de Dados
An Introduction to Statistical Learning (Python e R)



Pingback: Machine Learning from Scratch: Implementando Random Forest (Floresta Aleatória) em Python - IA Com Café