

O aprendizado de máquina, conhecido como machine learning em inglês, é uma área da Inteligência Artificial na qual sistemas são criados com a capacidade de aprender a partir de dados. Ao analisar uma quantidade crescente de informações, um programa de computador aprimora seu desempenho em uma tarefa específica. É basicamente isso!
Um algoritmo de machine learning é treinado com um grande volume de dados. A partir dessa análise, ele consegue identificar padrões e fazer previsões sobre dados novos, sem precisar de nenhuma instrução específica. É como se o programa “aprendesse” a realizar a tarefa por conta própria.
Um pouco da História

A origem do machine learning remonta à década de 1950, quando a computação ainda engatinhava. Foi nessa época que o matemático e pioneiro da computação Alan Turing teorizou sobre a capacidade das máquinas de exibirem inteligência. Turing é considerado um dos nomes mais importantes na área da Inteligência Artificial.
Paralelamente, outro marco importante foi o trabalho do cientista da computação Arthur Samuel. Ele é creditado por ter cunhado o termo “machine learning” em meados dos anos 1950. Samuel estava focado em criar máquinas que aprendessem a jogar damas sem precisarem de programação específica para cada movimento.
Outro grande salto veio em 1958 com o Perceptron, um modelo de rede neural artificial desenvolvido pelo psicólogo e cientista da computação Frank Rosenblatt. As redes neurais artificiais são inspiradas no cérebro humano e têm a capacidade de aprender a partir de exemplos. O Perceptron foi capaz de reconhecer padrões simples, pavimentando o caminho para o desenvolvimento de algoritmos de machine learning mais complexos.
Apesar desses avanços iniciais, o machine learning enfrentou períodos de pouco progresso devido às limitações computacionais da época. Foi somente com o aumento da capacidade de processamento e o surgimento de grandes volumes de dados que a área voltou a crescer de forma exponencial a partir dos anos 1990.
Categorias de Machine Learning

Aprendizado de máquina supervisionado
O aprendizado de máquina supervisionado é um tipo de aprendizado de máquina em que o modelo é treinado com um conjunto de dados rotulados. Isso significa que cada entrada no conjunto de dados tem um rótulo associado que indica a saída desejada.
O modelo aprende a mapear as entradas para as saídas desejadas, analisando os dados rotulados. Após o treinamento, o modelo pode ser usado para prever a saída para novas entradas que não foram vistas durante o treinamento.
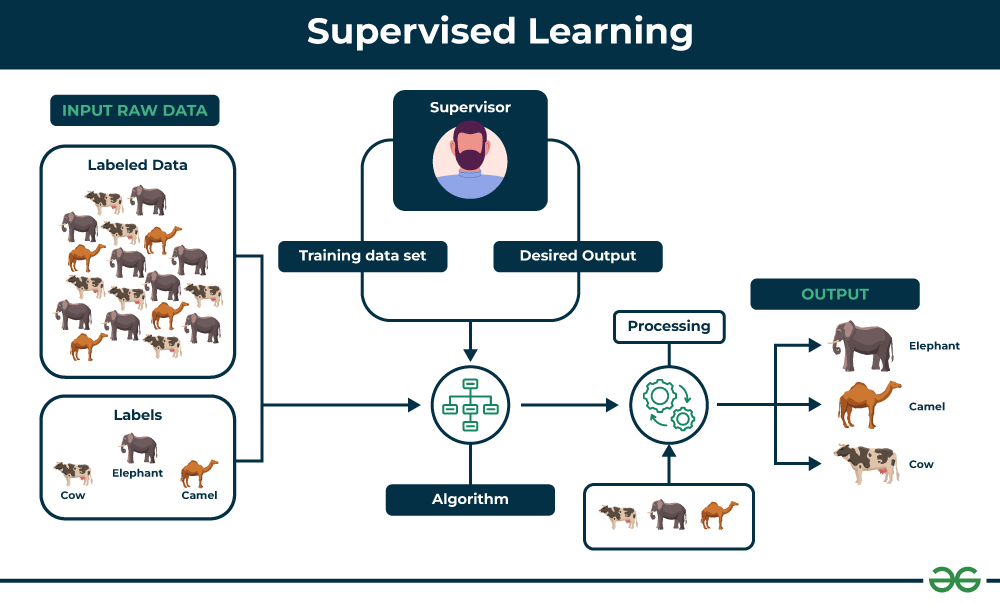
Existem dois tipos principais de aprendizado de máquina supervisionado:
- Classificação: o modelo aprende a classificar as entradas em diferentes categorias. Por exemplo, um modelo de classificação pode ser treinado para identificar imagens de gatos e cachorros.
- Regressão: o modelo aprende a prever um valor numérico. Por exemplo, um modelo de regressão pode ser treinado para prever o preço de uma casa com base em suas características.
Caso real de aplicação: Transações com cartão de crédito

As empresas de cartão de crédito lidam com o problema de fraude, onde transações fraudulentas são feitas usando cartões roubados ou informações de cartão vazadas. Detectar essas transações fraudulentas é crucial para proteger os clientes e minimizar perdas financeiras.
O aprendizado de máquina supervisionado pode ser aplicado para detectar transações fraudulentas em tempo real. Um modelo de aprendizado de máquina pode ser treinado em um conjunto de dados de transações, onde cada transação é rotulada como “fraudulenta” ou “legítima”.
Ao analisar padrões de transações, o modelo pode identificar transações fraudulentas com alta precisão e em tempo real, protegendo clientes e empresas.
Considerações importantes:
- Balanceamento de dados: É importante garantir que o conjunto de dados utilizado para treinar o modelo seja balanceado, com uma quantidade suficiente de exemplos para cada categoria da sua base de dados.
- Pré-processamento de dados: O pré-processamento dos dados, como normalização e limpeza, pode melhorar o desempenho do modelo.
- Seleção de features: A seleção das features mais relevantes para o problema de detecção de fraude pode melhorar a precisão do modelo e reduzir o tempo de treinamento.
- Avaliação do modelo: É importante avaliar o desempenho do modelo em um conjunto de dados de teste para garantir sua efetividade.
- Qualidade dos dados: A qualidade do conjunto de dados usado para treinar o modelo é crucial para sua precisão.
- Atualização constante: O modelo precisa ser atualizado constantemente com novas informações sobre para manter sua eficácia.
Exemplo de modelos populares:
Regressão Linear
Arvores de Decisão
Support Vector Machines (SVM)
Redes neurais artificiais
K-Nearest Neighbors (KNN)
Aprendizado de máquina não supervisionado
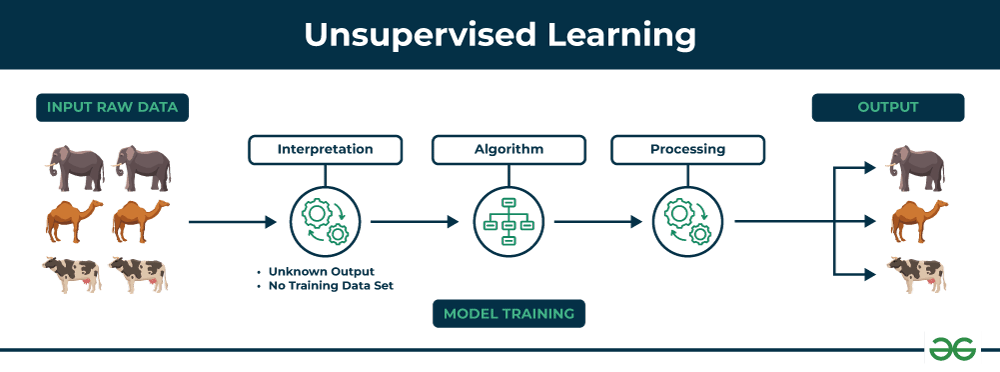
O aprendizado de máquina não supervisionado é um tipo de aprendizado de máquina em que o modelo é treinado em um conjunto de dados sem rótulos. Isso significa que o modelo não recebe nenhuma informação sobre as saídas desejadas.
Em vez disso, o modelo aprende a identificar padrões e estruturas nos dados por conta própria. O objetivo é descobrir insights escondidos nos dados que não seriam facilmente identificados por humanos.
Existem três tipos principais de aprendizado de máquina não supervisionado:
- Agrupamento (Clustering): O modelo aprende a agrupar dados em clusters com base em similaridades. Por exemplo, um modelo de clustering pode ser usado para agrupar clientes em diferentes segmentos de mercado.
- Redução de dimensionalidade: O modelo aprende a reduzir a dimensionalidade dos dados, preservando as informações mais importantes. Isso pode ser útil para visualizar dados complexos em um espaço bidimensional ou tridimensional.
- Detecção de anomalias: O modelo aprende a identificar pontos de dados que são diferentes dos demais. Isso pode ser útil para detectar fraudes ou falhas em sistemas.
O aprendizado de máquina não supervisionado é uma técnica poderosa para explorar dados e descobrir insights. No entanto, é importante ter em mente que o modelo não é capaz de interpretar os padrões que ele identifica. A interpretação dos resultados é de responsabilidade do cientista de dados e das pessoas envolvidas.
O aprendizado de máquina não supervisionado é usado em uma ampla variedade de aplicações, como:
- Análise de mercado: identificar segmentos de mercado e entender o comportamento do consumidor.
- Descoberta de conhecimento: encontrar padrões e insights em grandes conjuntos de dados.
- Manutenção preditiva: identificar anomalias que podem indicar falhas em sistemas.
Caso real de aplicação: Varejo

Imagine uma empresa de varejo que possui um grande conjunto de dados de transações de clientes. A empresa pode usar o aprendizado de máquina não supervisionado para identificar diferentes segmentos de clientes com base em seus hábitos de compra. Essa informação pode ser usada para direcionar campanhas de marketing de forma mais eficaz.
Benefícios:
- Descoberta de insights: O aprendizado de máquina não supervisionado pode ajudar a descobrir insights que não seriam facilmente identificados por humanos.
- Identificação de padrões: O aprendizado de máquina não supervisionado pode ajudar a identificar padrões nos dados que podem ser úteis para tomar decisões.
- Redução de custos: O aprendizado de máquina não supervisionado pode ser usado para reduzir custos, automatizando tarefas que de outra forma seriam realizadas por humanos.
Limitações:
- Interpretação: Os modelos de aprendizado de máquina não supervisionados podem ser difíceis de interpretar.
- Qualidade dos dados: A qualidade dos dados é crucial para o sucesso do aprendizado de máquina não supervisionado.
- Tempo de treinamento: O treinamento de modelos de aprendizado de máquina não supervisionados pode ser demorado.
Exemplo de Algorítimos populares:
K-Means Clustering
DBSCAN Algorithm
Principal Component Analysis (PCA)
Independent Component Analysis
Aprendizado de máquina semi supervisionado
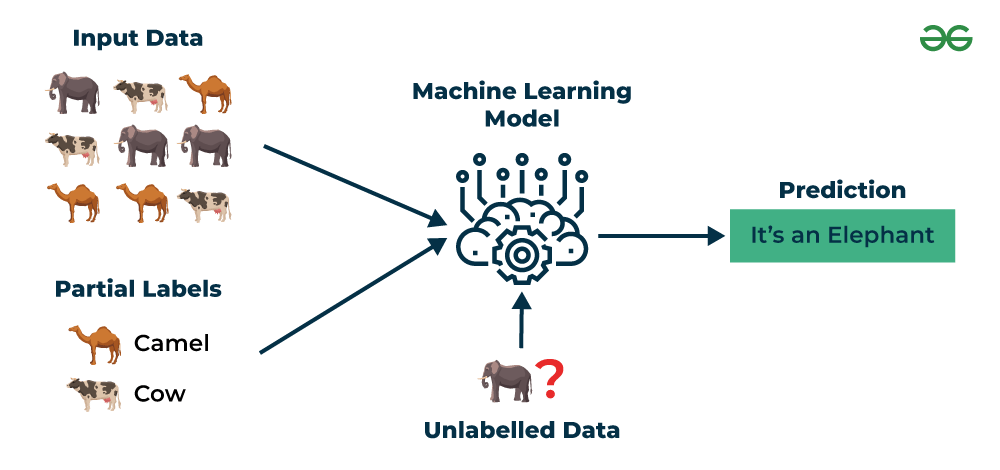
O aprendizado de máquina semi-supervisionado é um tipo de aprendizado de máquina que combina os princípios do aprendizado de máquina supervisionado e não supervisionado. Nesse tipo de aprendizado, o modelo é treinado em um conjunto de dados que contém alguns dados rotulados e outros não rotulados.
O objetivo do aprendizado de máquina semi-supervisionado é utilizar os dados rotulados para fornecer ao modelo um conhecimento inicial sobre a tarefa que ele precisa realizar, e então utilizar os dados não rotulados para complementar esse conhecimento e melhorar o desempenho do modelo.
Existem diversas técnicas de aprendizado de máquina semi-supervisionado, como:
- Marcação pseudo-rotulada: O modelo utiliza os dados rotulados para aprender a classificar os dados não rotulados.
- Propagação de rótulos: O modelo utiliza os dados rotulados para propagar rótulos para os dados não rotulados.
- Co-treinamento: O modelo utiliza dois ou mais modelos diferentes para aprender com os dados rotulados e não rotulados.
O aprendizado de máquina semi-supervisionado pode ser utilizado em diversas aplicações, como:
- Classificação de texto: Classificar documentos em diferentes categorias, mesmo quando há um número limitado de documentos rotulados.
- Segmentação de imagens: Segmentar imagens em diferentes regiões, mesmo quando há um número limitado de imagens rotuladas.
- Recomendação de sistemas: Recomendar produtos ou serviços aos usuários, mesmo quando há um número limitado de dados sobre as preferências dos usuários.
O aprendizado de máquina semi-supervisionado pode ser uma técnica vantajosa em diversas situações, como:
- Quando há um número limitado de dados rotulados: O aprendizado de máquina semi-supervisionado pode ser utilizado para melhorar o desempenho do modelo mesmo quando há um número limitado de dados rotulados disponíveis.
- Quando os dados não rotulados são abundantes: O aprendizado de máquina semi-supervisionado pode ser utilizado para aproveitar a grande quantidade de dados não rotulados que geralmente estão disponíveis.
- Quando a rotulagem de dados é cara ou demorada: O aprendizado de máquina semi-supervisionado pode reduzir o custo e o tempo da rotulagem de dados.
Aprendizado de máquina por reforço
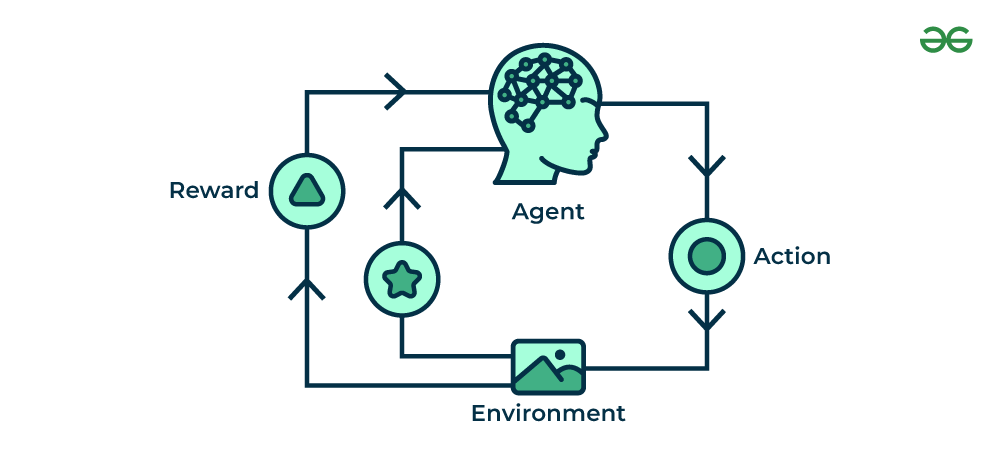
O Aprendizado de Máquina por Reforço (RL) é um tipo de aprendizado de máquina que permite que um agente aprenda a tomar decisões em um ambiente para maximizar uma recompensa. O agente aprende por tentativa e erro, interagindo com o ambiente e recebendo recompensas ou penalidades por suas ações.
O RL é diferente de outros tipos de aprendizado de máquina porque não há um conjunto de dados rotulado para treinar o modelo. Em vez disso, o agente aprende com sua própria experiência, explorando o ambiente e descobrindo quais ações são mais recompensadoras.
O RL pode ser usado para resolver diversos problemas, como:
- Jogos: Ensinar um agente a jogar um jogo de forma competitiva.
- Robótica: Controlar um robô para realizar tarefas complexas.
- Finanças: Gerenciar um portfólio de investimentos.
- Manufatura: Otimizar o processo de produção.
O RL é um campo de pesquisa ativo e muitos novos algoritmos e técnicas estão sendo desenvolvidos constantemente.
Alguns dos principais componentes do RL são:
- Agente: O agente é o “aprendiz” no sistema RL. É o responsável por tomar decisões e interagir com o ambiente.
- Ambiente: O ambiente é o mundo em que o agente opera. Ele fornece ao agente feedback sobre suas ações.
- Recompensa: A recompensa é um sinal que o ambiente fornece ao agente para indicar a qualidade de suas ações.
- Política: A política é a estratégia que o agente usa para tomar decisões.
- Função de valor: A função de valor é uma estimativa da recompensa que o agente espera receber ao longo do tempo.
O processo de aprendizado no RL geralmente funciona da seguinte maneira:
- O agente toma uma ação no ambiente.
- O ambiente fornece ao agente uma recompensa.
- O agente atualiza sua política com base na recompensa.
- O agente repete os passos 1 a 3 até que a política converja para uma solução ótima.
O RL é uma técnica poderosa que pode ser usada para resolver diversos problemas complexos. No entanto, é importante ter em mente que o RL pode ser um processo desafiador, pois exige que o agente explore o ambiente e aprenda com seus erros.
Algumas das vantagens do RL incluem:
- Flexibilidade: O RL pode ser aplicado a uma ampla variedade de problemas.
- Eficiência: O RL pode aprender soluções ótimas ou quase ótimas para problemas complexos.
- Robustez: O RL pode lidar com ambientes incertos e dinâmicos.
Algumas das desvantagens do RL incluem:
- Complexidade: O RL pode ser um processo desafiador de implementar e entender.
- Tempo de treinamento: O RL pode levar muito tempo para aprender soluções ótimas.
- Interpretabilidade: Os modelos de RL podem ser difíceis de interpretar.
Caso real de aplicação: Robô que aprende a andar

Imagine um robô que precisa aprender a andar por conta própria. O robô não tem nenhuma informação sobre como andar, e precisa descobrir como se mover de forma eficiente e segura.
O aprendizado de máquina por reforço pode ser usado para ensinar o robô a andar. O robô pode ser modelado como um agente que interage com o ambiente. O ambiente pode ser modelado como um simulador físico que fornece feedback ao robô sobre sua posição, velocidade e outras informações relevantes.
O robô pode começar explorando o ambiente aleatoriamente. Ao se mover, o robô recebe recompensas do ambiente por se manter equilibrado e por se mover em direção a um objetivo. O robô também recebe penalidades por cair ou por se mover muito lentamente.
Com o tempo, o robô aprende a associar suas ações com as recompensas e penalidades que recebe. O robô aprende a ajustar suas ações para maximizar as recompensas e minimizar as penalidades.
Exemplo de modelos populares:
Q-learning
SARSA (State-Action-Reward-State-Action)
Deep Q-learning
Conclusão
Em suma, os diversos tipos de aprendizado de máquina se complementam para impulsionar o desenvolvimento de capacidades avançadas de previsão de dados. Através de suas diferentes abordagens e pontos fortes, cada tipo contribui para o progresso da Ciência de Dados e abre portas para a transformação de diversos setores.
A capacidade de lidar com a produção massiva de dados e gerenciar conjuntos de dados complexos é fundamental na era digital. O aprendizado de máquina oferece ferramentas e soluções inovadoras para extrair insights valiosos desses dados, impulsionando a tomada de decisões inteligentes e abrindo caminho para novos avanços científicos e tecnológicos.
Existem muitas fontes interessantes para que você possa se aprofundar cada vez mais no mundo do aprendizado de máquina, sugiro da uma conferida na nossa página de livros recomendados, bons estudos e bom café!




Pingback: Machine Learning from scratch: Implementando o KNN (K vizinhos mais próximos) em Python - IA Com Café
Pingback: A Importância da Validação Cruzada em Machine Learning - IA Com Café
Pingback: Criando seu primeiro projeto de machine learning com deploy: Parte 1 - IA Com Café
Pingback: Regularização em Machine Learning: Técnicas e Benefícios para Modelos Mais Robustos - IA Com Café
Pingback: Machine Learning from scratch: Implementando o SVM (Máquinas de Vetores de Suporte) em Python - IA Com Café
Pingback: Top livros que todo Cientista de Dados deveria ter - IA Com Café
Pingback: Entendendo o Label encoding em machine learning - IA Com Café
Pingback: Como se preparar para uma entrevista de ciência de dados: Guia completo com dicas e estratégias - IA Com Café
Pingback: 5 dicas para melhorar a preparação dos seus dados em projetos de machine learning - IA Com Café
Pingback: O que são Modelos Paramétricos e Não Paramétricos em machine learning - IA Com Café
Pingback: Otimização de Hiperparâmetros: Grid Search, Random Search e Bayesian Optimization - IA Com Café
Pingback: Data Leakage e Target Leakage: O que são e como evitá-los no machine learning - IA Com Café